
The Grenadier, Hailsham
© Copyright Oast House Archive and licensed for reuse under this Creative Commons Licence.
前回は、Azure Prompt Flowの、チャット用標準テンプレート(Chat flow)を実際に使ってみた結果をご覧いただきました。今回は、評価フローテンプレート(Evaluation flow)を実際に使ってみた例をご覧いただこうと思っていたのですが。。。
他の2つの標準テンプレートとは異なり、Azure Prompt flowが現在提供している評価フローテンプレートはそのまま実行しても何かを評価できるようなサンプルとはなっていませんでした。また、このテンプレートでは、Pythonのモジュールしかなく、GPTを呼び出すLLMモジュールがないので、単に何かを実行するPythonのプログラムの実装において、複数の処理ロジックをバリアント0,バリアント1、・・・のように作成して、それらのPythonプログラムのパフォーマンスを比較するというような使い方になると思われますが、とりあえず、まずは、評価フローテンプレートを「Create」した結果をご覧いただきましょう。
■評価フローテンプレート(Evaluation flow)の選択
Prompt flow画面の呼び出しと、新しいプロンプト用のPrompt flowを作成するための画面は、前回もご紹介した通りです。Prompt flowの画面で「+ Create」をクリックすると下の画面(Create a new flow)がポップアップします。
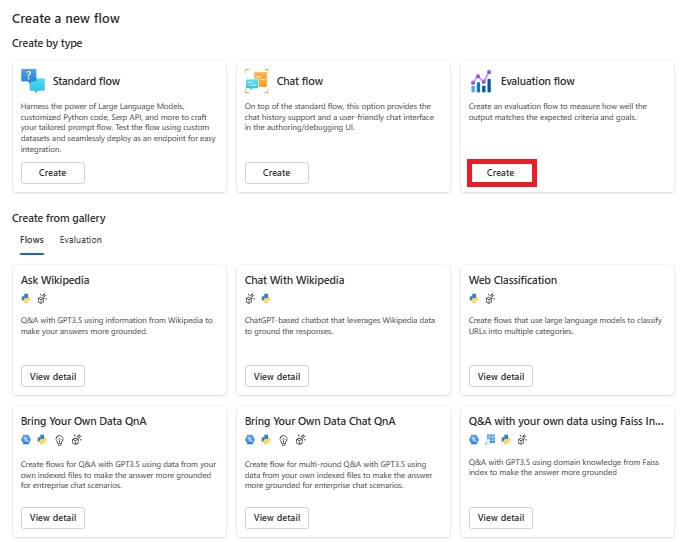
■評価フローテンプレート(Evaluation flow)の利用
上図中、「Evaluation flow」にある、赤枠で囲った「Create」ボタンをクリックすると、以下の画面に切り替わります。
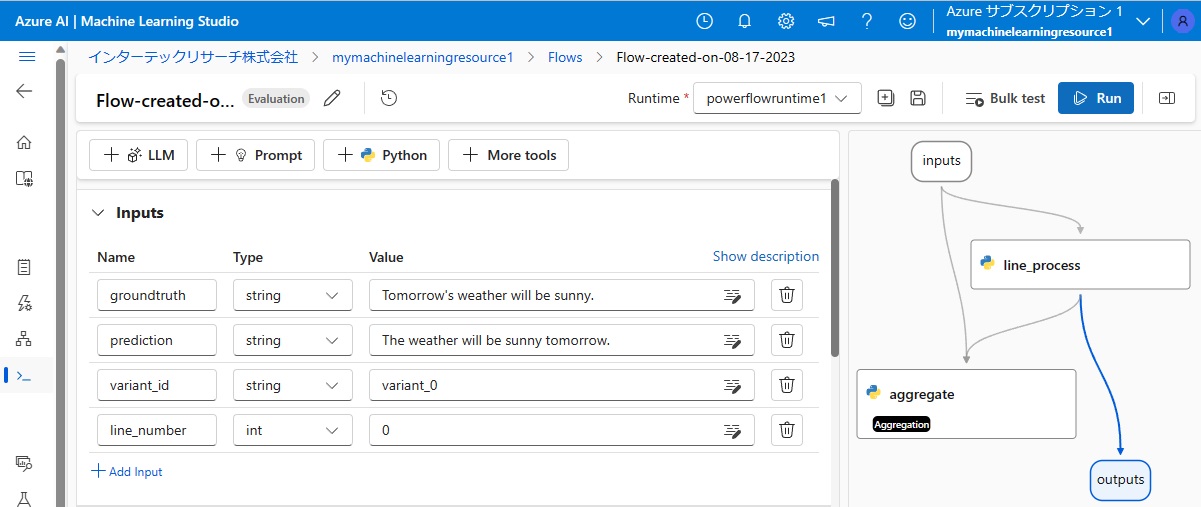
評価フローテンプレートのPrompt flowは、画面右側のビジュアルインタフェース部分で示されている通りです。
■サンプル入力:inputs
このテンプレートでは、上図中央の「Inputs」欄にあるように入力データが4つあり、
・データ名:groundtruth、データ型:string、初期値:Tomorrow’s weather will be sunny.
・データ名:predictions、データ型:string、 初期値:The weather will be sunny tomorrow.
・データ名:variant_id、データ型:string、初期値:variant_0
・データ名:line_number、データ型:intリストで、初期値は0
となっています。
■Pythonプログラム:line_process
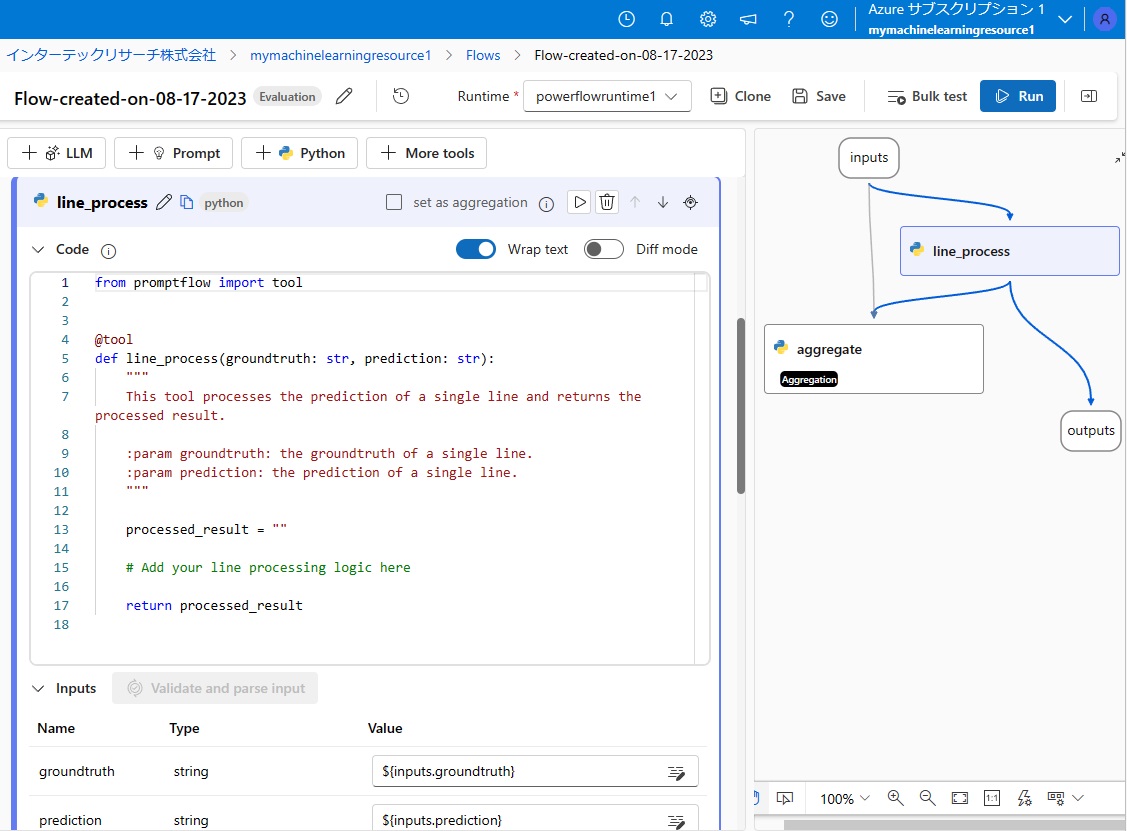
「line_process」は、ご覧の通りのPythonプログラムで、現状では常に空を出力するだけ(processed_result = “”)となっています。
■Pythonプログラム:aggregate
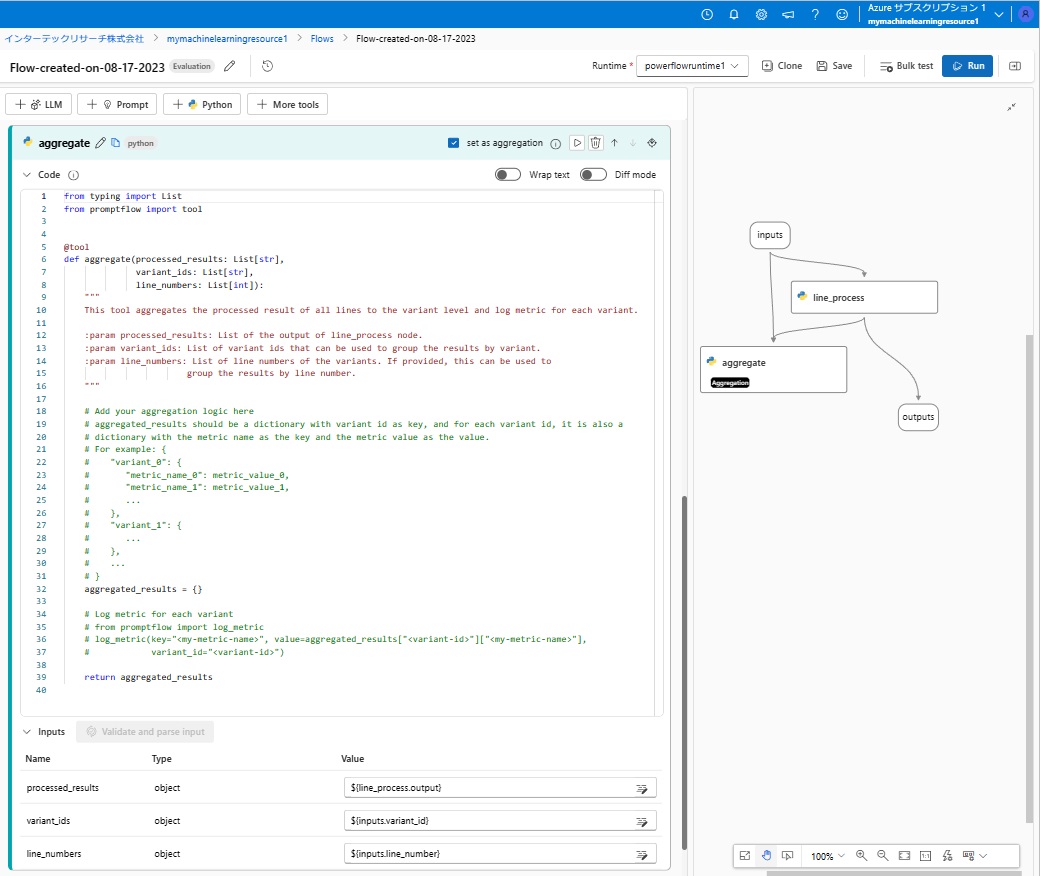
「aggregate」は、ご覧の通りのPythonプログラムで、現状では常に空を出力するだけ(aggregated_result = {})となっています。
■サンプル出力:outputs
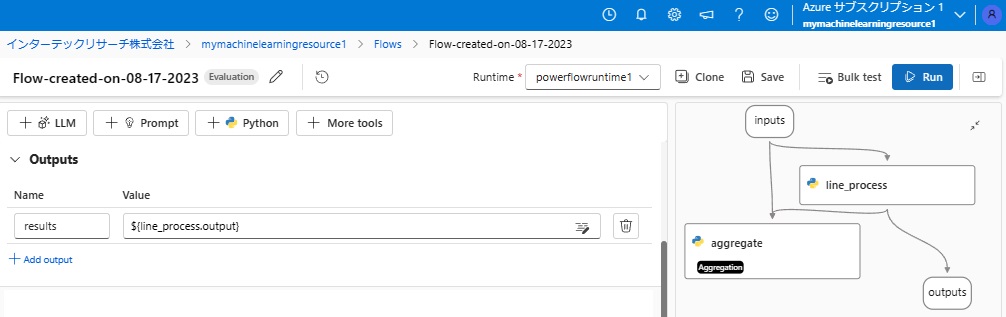
画面中央の「Outputs」欄に、データ名:results、値として「line_process」の出力(${line_process.output})が設定されていますので、テンプレートのままこのプロンプトフローを実行すると、line_processから渡されたデータがそのまま出力されることになります。
Prompt flowが提供する評価フローテンプレートは以上の通りで、あまりこれをベースにしても使い勝手が良くない感じです。
■評価のベースとなるプロンプトフローの作成
そこで、前回ご紹介したチャット用標準テンプレート(Chat flow)をベースとして、LLMを呼び出して入力テキストの内容をpositive/neutral/negativeに分類するプロンプトを評価するためのプロンプトフローを作成しました。
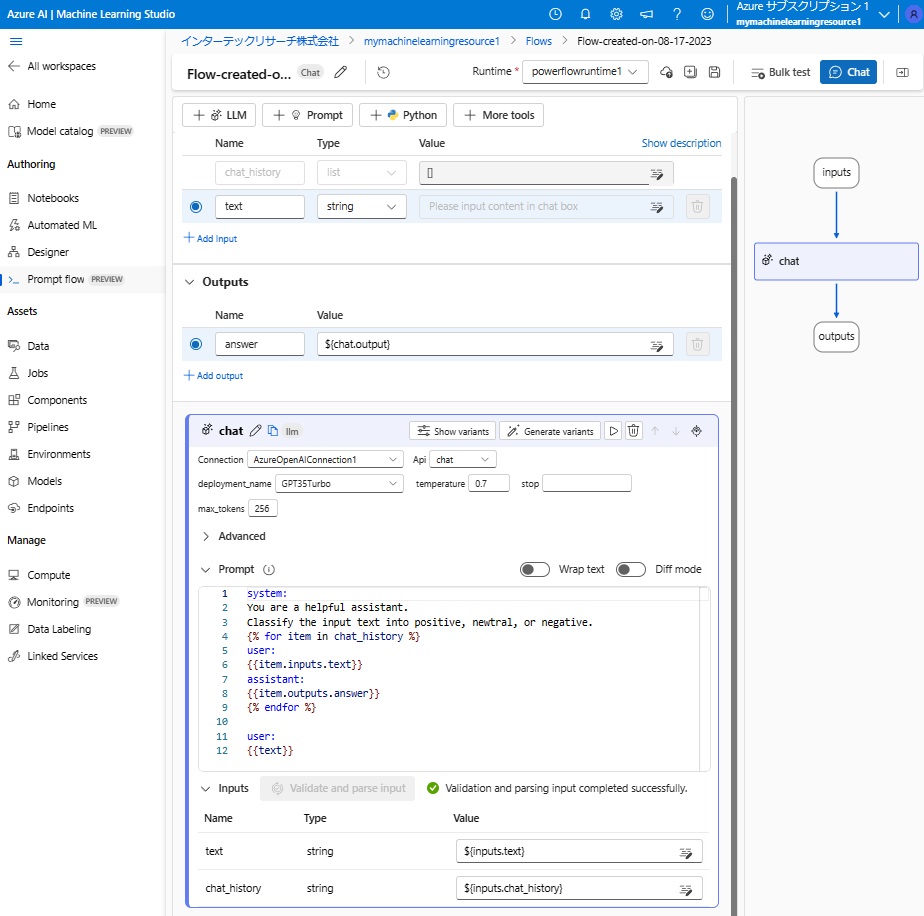
上図画面中央の「chat」の帯に「Show variants」と「Generate variants」というのがあるので、「Generate variants」にカーソルを当てると、以下の説明が表示されました。

この説明によると、Prompt flowが自動的に、「Prompt」欄の内容を見て、そのバリエーションのプロンプトを作ってくれるようです。これは便利ですね。
そこで、「Generate variants」をクリックすると、以下の画面がポップアップして表示されました。
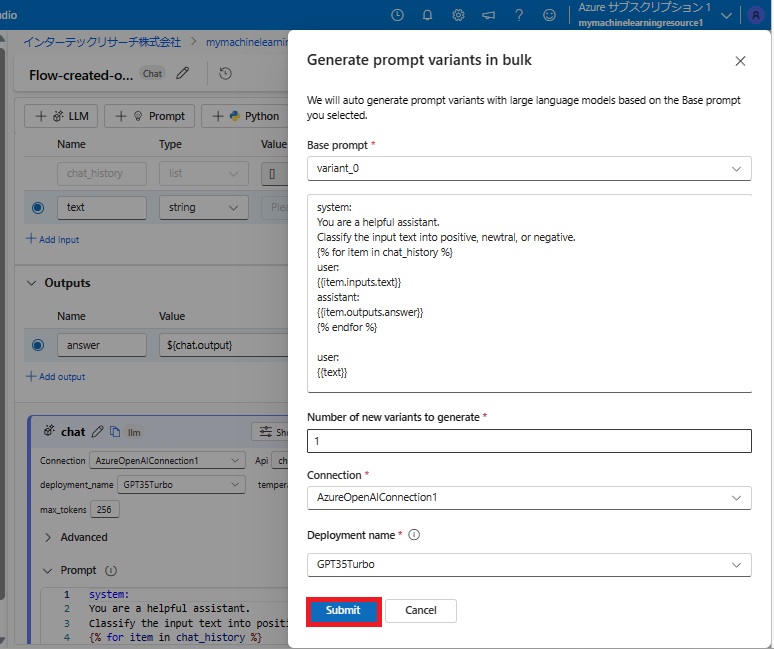
赤枠で囲った「Submit」をクリックし、いよいよプロンプトのバリエーションの自動生成を開始です!
ところが、エラーとなってしまいました。
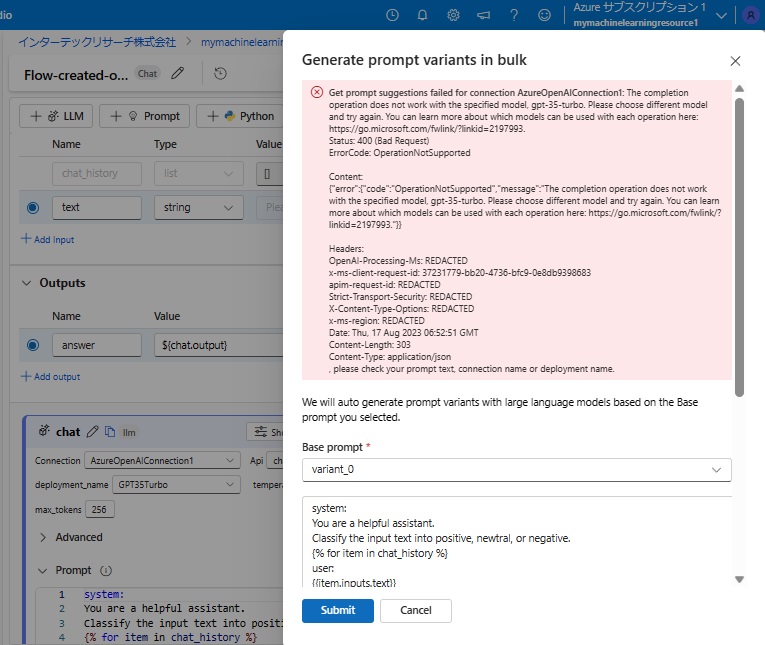
エラーメッセージの説明によると、OpenAI Serviceで使っているGPT3.5Turboモデルでは、プロンプトバリエーションの自動生成は行えないとのこと。誠に残念!
仕方なく、「Cancel」をクリックし、元の画面で「chat」の帯上にある「Show variants」をクリックしたところ、「chat」の帯の下に「Default variant_0」と表示され、「Clone」というボタンも現れました。
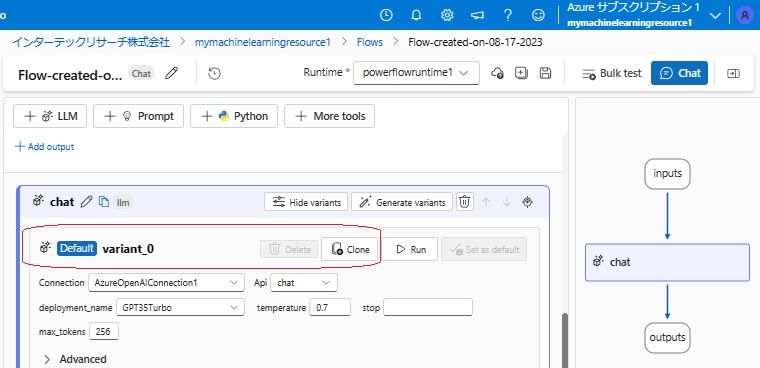
そこで、「Clone」をクリックすると、variant_0のクローンがvariant_1として作成されました。
また、ビジュアルインタフェース上、「chat」モジュールにバリエーションができたので、ボックスが二重になっています。
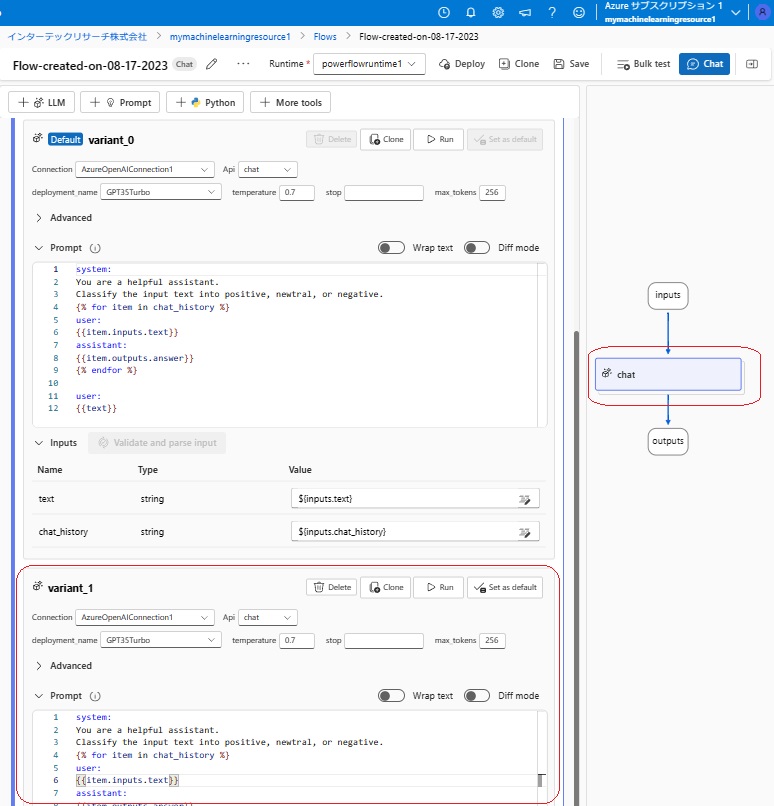
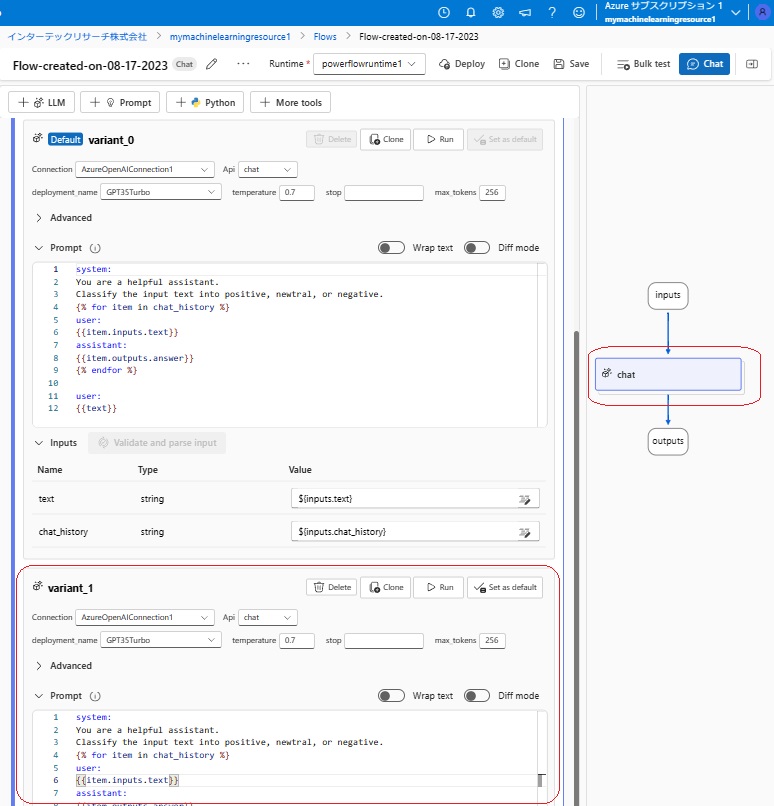
Variant_1のプロンプトは、次のようにfew-shotプロンプトにしてみました。
そして、3種類のテキストをチャット欄に入力した結果がこちらです。
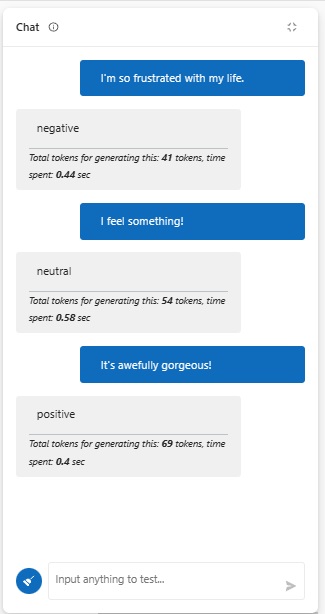
それぞれ、プロンプトとしてGPTにわたったトークン数とGPTからの回答のトークン数の合計と、処理に要した時間が出ていますが、これらは、元のzero-shotプロンプトの実行結果で、処理時間は0.4~0.58秒、GPTで処理したトークン数は41~69だったことが分かります。
次に、下図の赤枠で囲った「Set as Default」をクリックして、variant_1のプロンプトで、同じテキストの分類をしてみました。
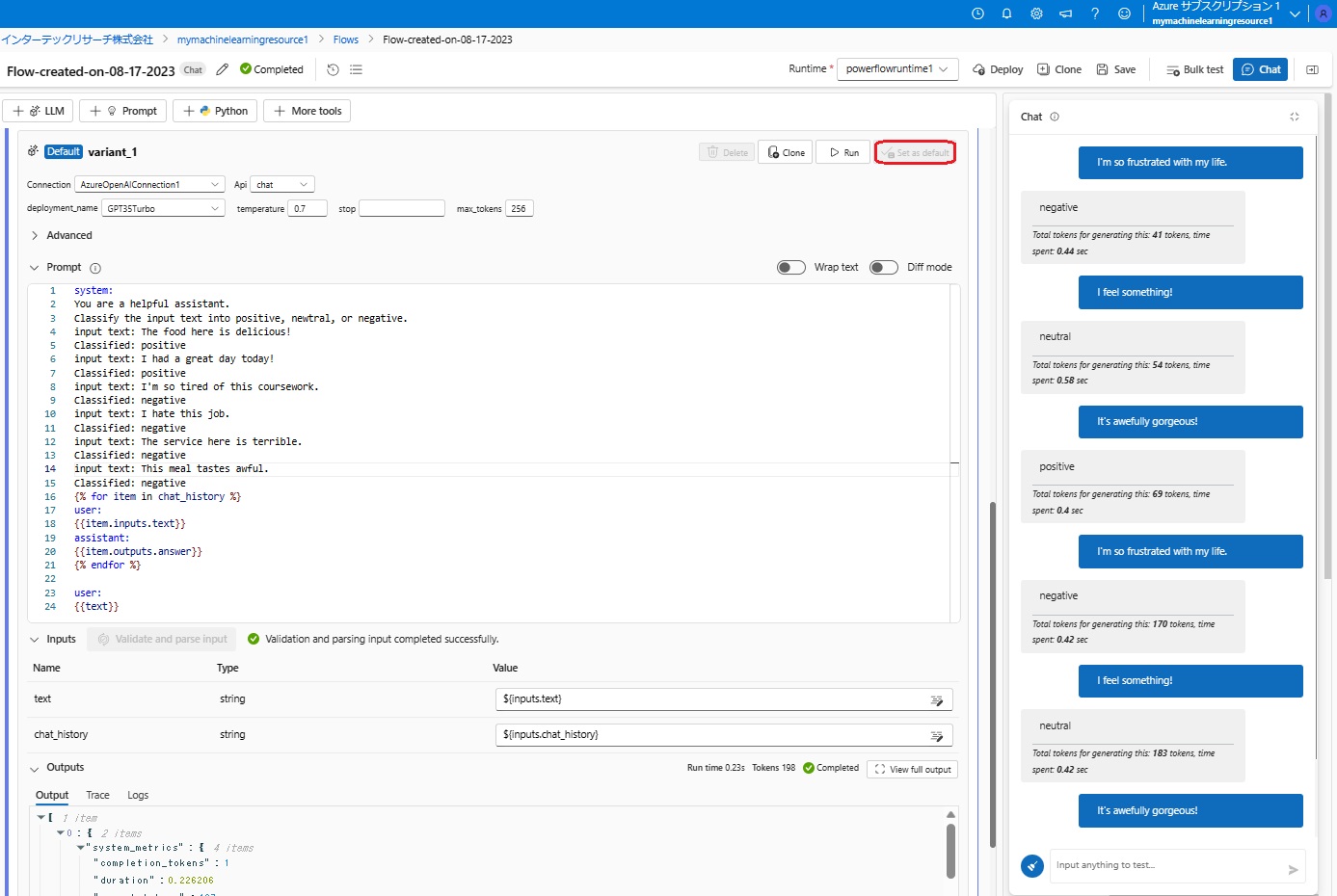
3種類のテキストの分類に要した時間(Time spentの値)を比較すると、やはりvariant_1のfew-shotプロンプトの方が若干早くなることが分かります。(3番目のテキストに関してはvariant_0の方が0.02秒早いですが)
ただし、GPTが処理したトークン数は、variant_1の方がvariant_0の1.7~3倍強となっています。
GPTの課金はトークン数に比例するので、複数のプロンプトの評価を行う場合、回答が出るまでの時間だけでなく、GPTの課金の多寡も勘案する必要があると思います。そうすることで、複数のプロンプトを、単に好みや感覚だけでなく、数値に直して評価することが可能となります。その意味で、Prompt flowは、正にプロフェッショナルな「プロンプトエンジニアリング」のためのツールであると言えるのではないでしょうか?
本日は以上です。
終わり
