
Tweeddale, Altarstone
© Copyright Richard Webb and licensed for reuse under this Creative Commons Licence.
「Difyについてーその4」では、とりあえず1つの情報源を利用したRAGアプリを構築し、試してみました。
今回は、「Difyについてーその3」で作成した、Dify.AIがドキュメントとして公開している複数の情報源を同時に参照して、その中から一番質問の回答にマッチする情報を生成AIに渡すRerank型のRAGアプリを構築し、試してみようと思います。
実際に構築作業に入る前に、まず、Rerankに関する情報の整理と、DifyでRerank機能を使う場合の手順を確認しておきましょう。
「CohereのRerank 3について」のブログ記事を作成した時点では、まだDifyを知らなかったので、知識として「Rerankというのは、こんなものだ」という感じでお伝えしたのですが、Difyでナレッジの登録をする際、「あ、これがRerank3なのか!」と腑に落ちました。
ただ、最初からいきなりDifyが提供する機能の詳細に立ち入ると、Difyの全体像が見えなくなるので、「その3」では、ナレッジ登録作業のディテールにはわざと触れないでおきました。
そこで、以下に、まず、その3でどのような作業を行ったのか見ていただこうと思います。
下図は、「1-Welcome to Dify!」のナレッジ登録時の設定画面です。
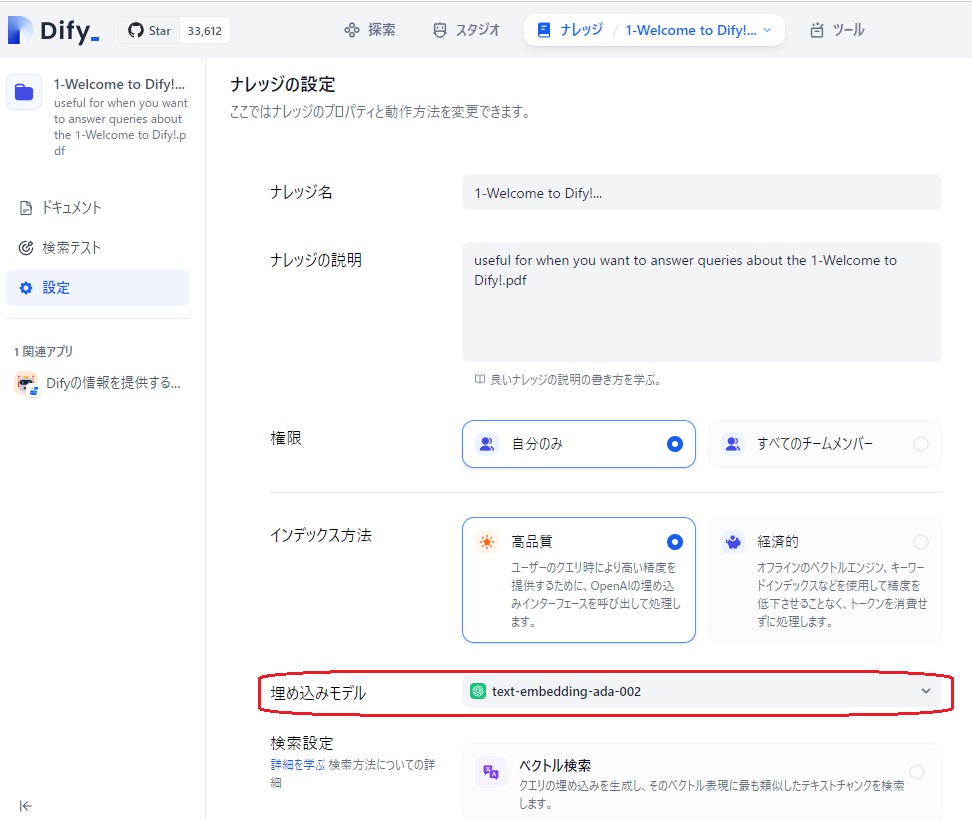
簡単に説明しておくと、Difyは、RAG情報をチャンクと呼ばれる適当な長さに分割して保持するのですが、後で、入力された質問によく似たチャンクを見つけるために、チャンク達はベクトル化されてデータが保持されるようです。
上図中、「インデックス方法」に「高品質」と「経済的」というのがありますが、「経済的」の方をクリックすると、チャンク達のベクトル化作業にあたって、Difyが用意した無償のツールが使われるようです。「高品質」をクリック(上図のように、「高品質」側が青線で囲われた状態)の場合は、有料の埋め込みモデルが使われます。
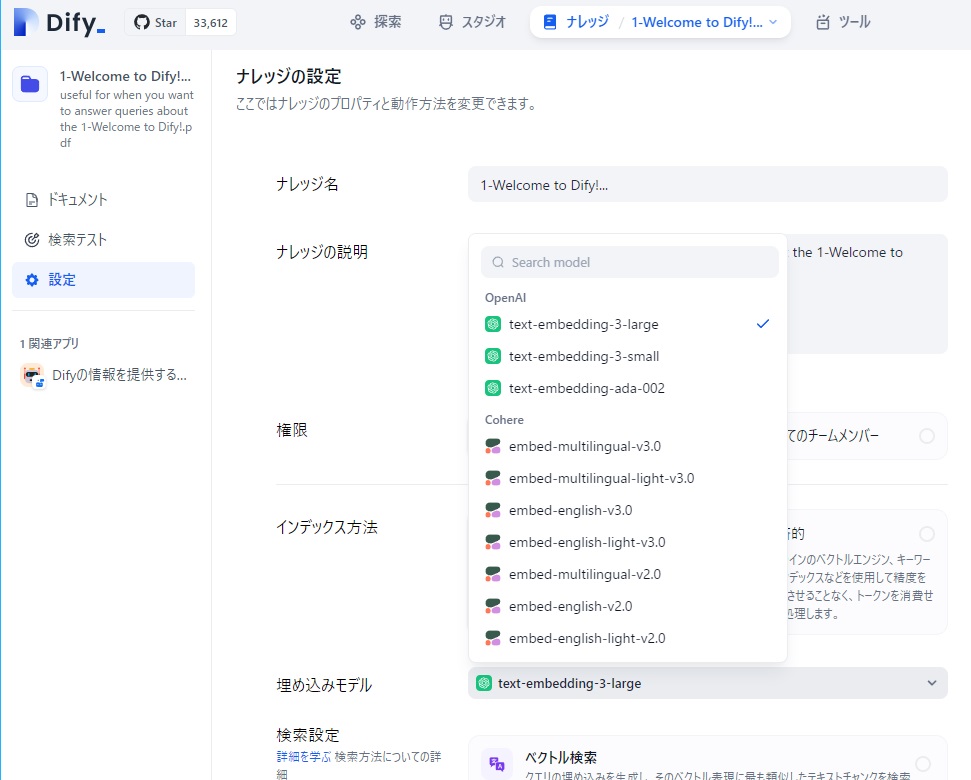
「高品質」を選んだ場合、デフォルトの埋め込みモデルはOpenAIの「text-embedding-ada-002」になっていましたが、他のDify紹介サイトでの推奨に従って、OpenAIの「text-embedding-3-large」に変更しました。
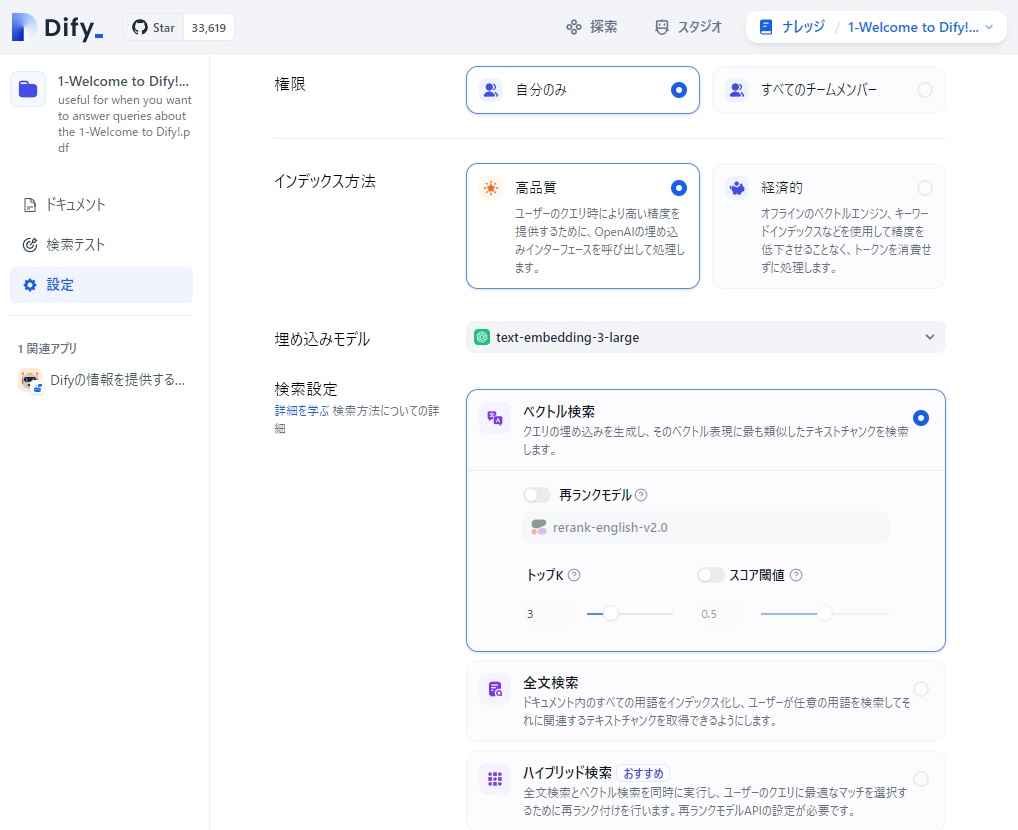
で、その下の「検索設定」ですが、「ベクトル検索」をクリックすると、デフォルトでは、「再ランクモデル」が未使用(スイッチがオフの状態)になっています。
最終的に、入力の質問に関して複数のDifyに関するナレッジを基に再ランク付けを行って最適な情報を次の生成AIに渡したいので、「再ランクモデル」のスイッチをオンにし、モデルとしてはCohereのreank-multilingual-v3.0を選択しました。
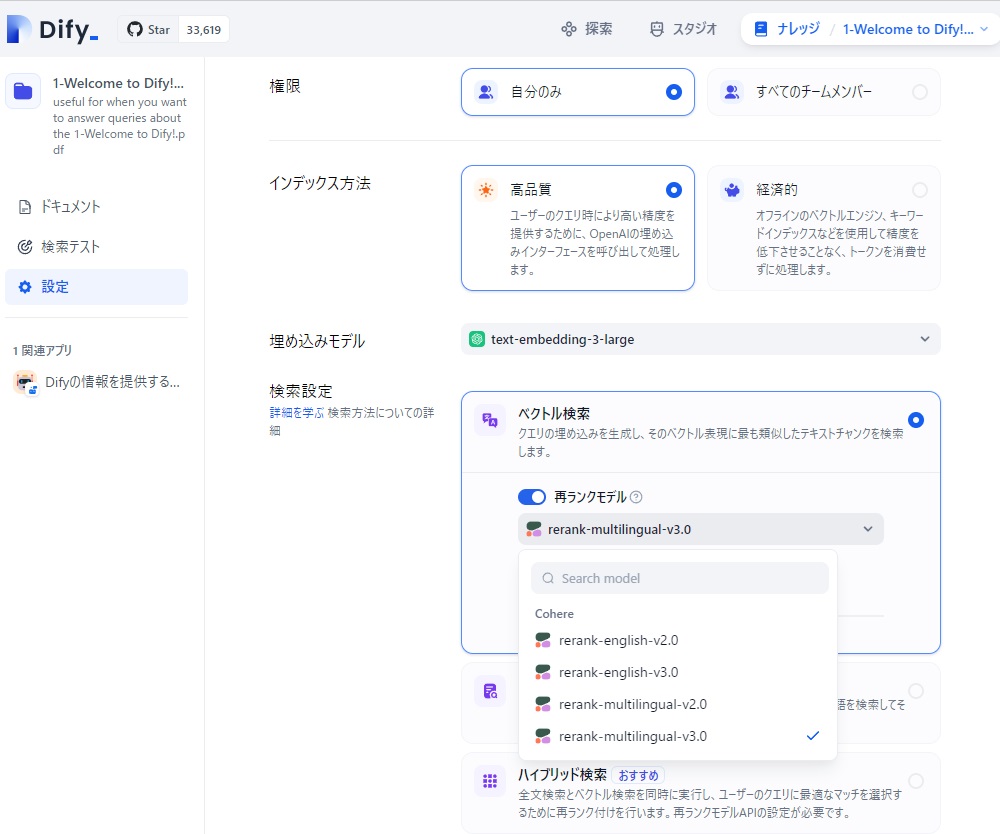
この、「rerank-multilingual-v3.0」が、CohereのRerank3の事だったんですね。
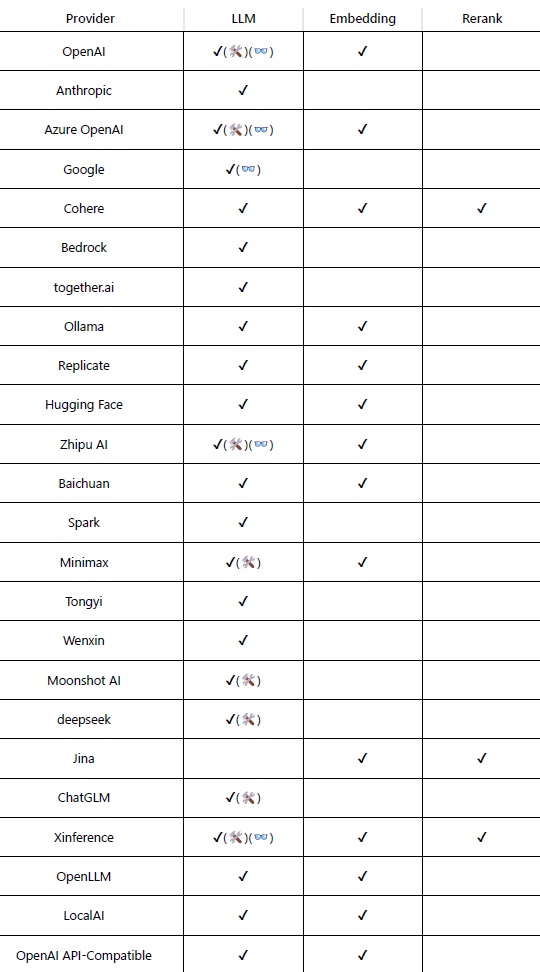
#なお、埋め込みモデルでは、OpenAIのモデルとCohereのモデルが表示されましたが、再ランクモデルでは、OpenAIのモデルは見当たりません。まだ、再ランクモデルを提供する生成AIのプロバイダは少ないようです。2024年6月現在はCohereを含めて3社しか再ランクモデルをサポートしていないようです。➡ご参考
同じように、Dify.AIの「ドキュメント」として提供されている情報も、OpenAIの埋め込みモデルでベクトル化し、検索時にはCohereの「rerank-multilingual-v3.0」を使うように設定し、「その3」の作業を完了しました。
では、再ランクモデルを利用したDify専用のRAGアプリを作ってみましょう。
前回同様、Difyの「探索(Difyによるアプリの探索)」で表示されたテンプレートの内、「Knowledge Retrieval + Chatbot」を使って、テストアプリを定義していきます。
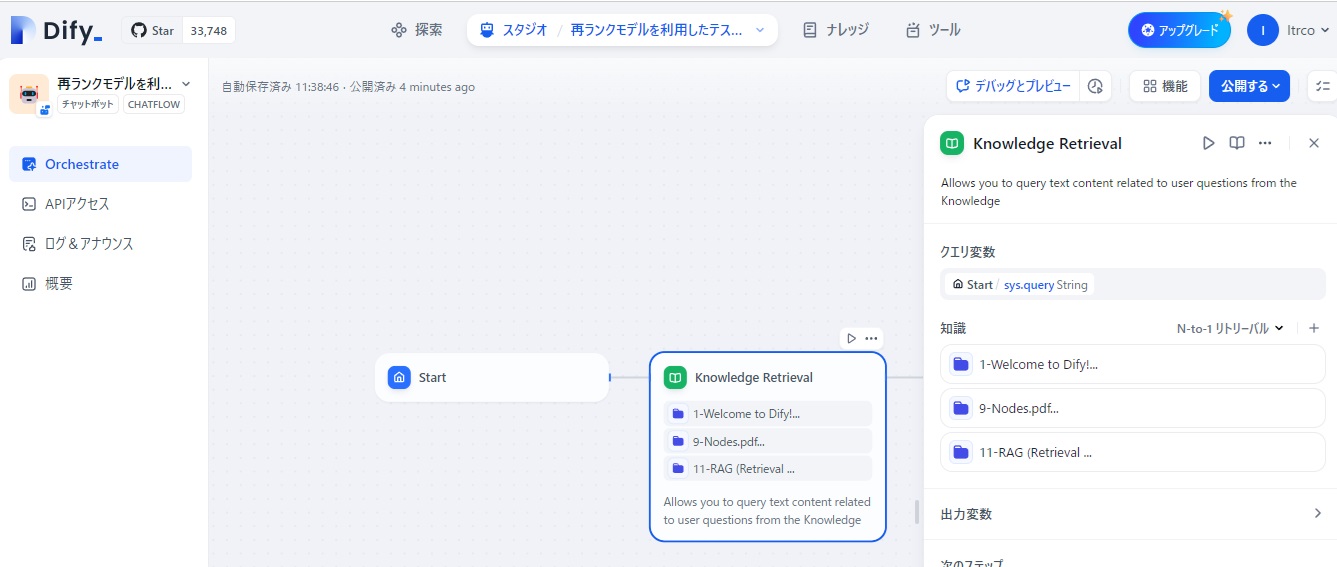
まず、知識獲得(Knowledge Retrieval)のノード設定で、「知識」として、Difyのドキュメントから試しに以下の3つの情報を登録しました。
そして、再ランクモデルを利用するため、デフォルトで設定されている「N-to-1リトリーバル」の部分をクリックし、「マルチパスリトリーバル」に切り替えるとともに、「再ランクモデル」がCohereの「rerank-ultilingual-3.0」に設定します。
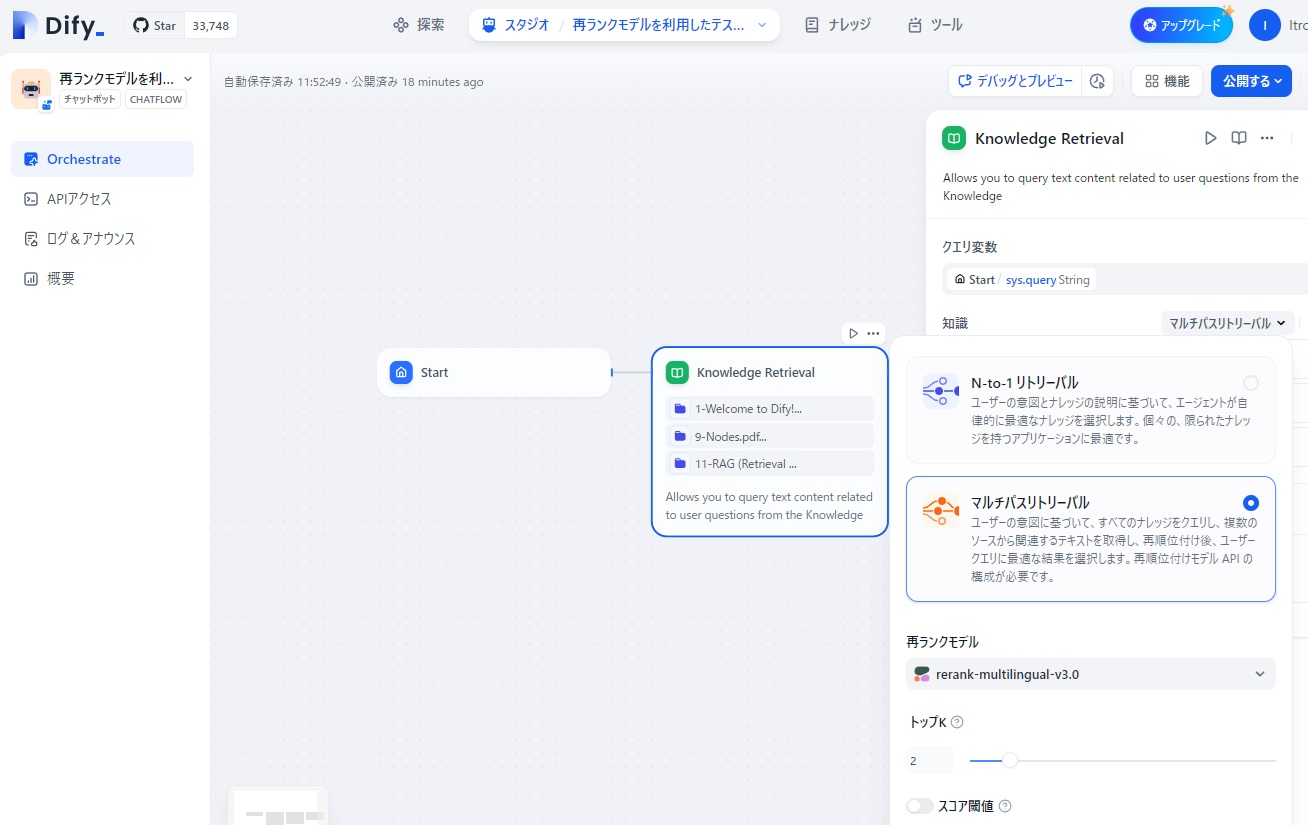
また、LLMの設定では、「モデル」を「gpt-4o-024-05-13」に、「コンテキスト」にKnowledge Retrievalの出力である「result」を設定しました。
これで、再ランクモデルのRAGアプリ完成です!
では、早速、再ランクモデルがうまく動いているか、確認してみましょう。
再ランクモデルでは、ナレッジとして登録した①1-Welcome to Dify!、②9-Nodes、③11-RAG (Retrieval Augmented Generation)の情報から、質問に関連の深い「チャンク」を検索したのち、それらを再ランク付けして、一番質問に関連すると思われるものがLLMに渡されるはずです。
「デバッグとプレビュー」をクリックし、プロンプト入力欄に「Difyでの「知識獲得」の使い方について説明してください。」と入力すると、下図のように回答が返されました。
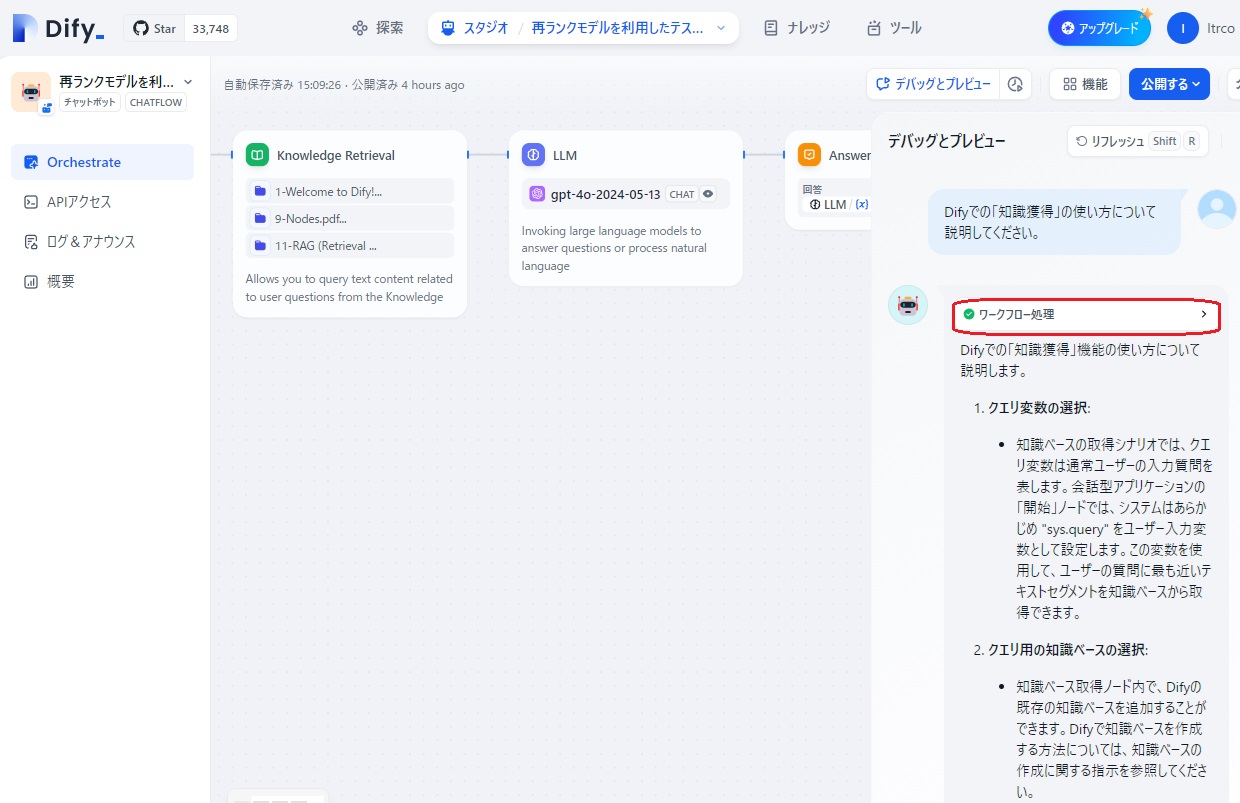
再モデル機能がうまく働いているかどうか確認するため、「ワークフロー処理」の部分をクリックすると、ワークフローを構成する4つのノードが表示されます。
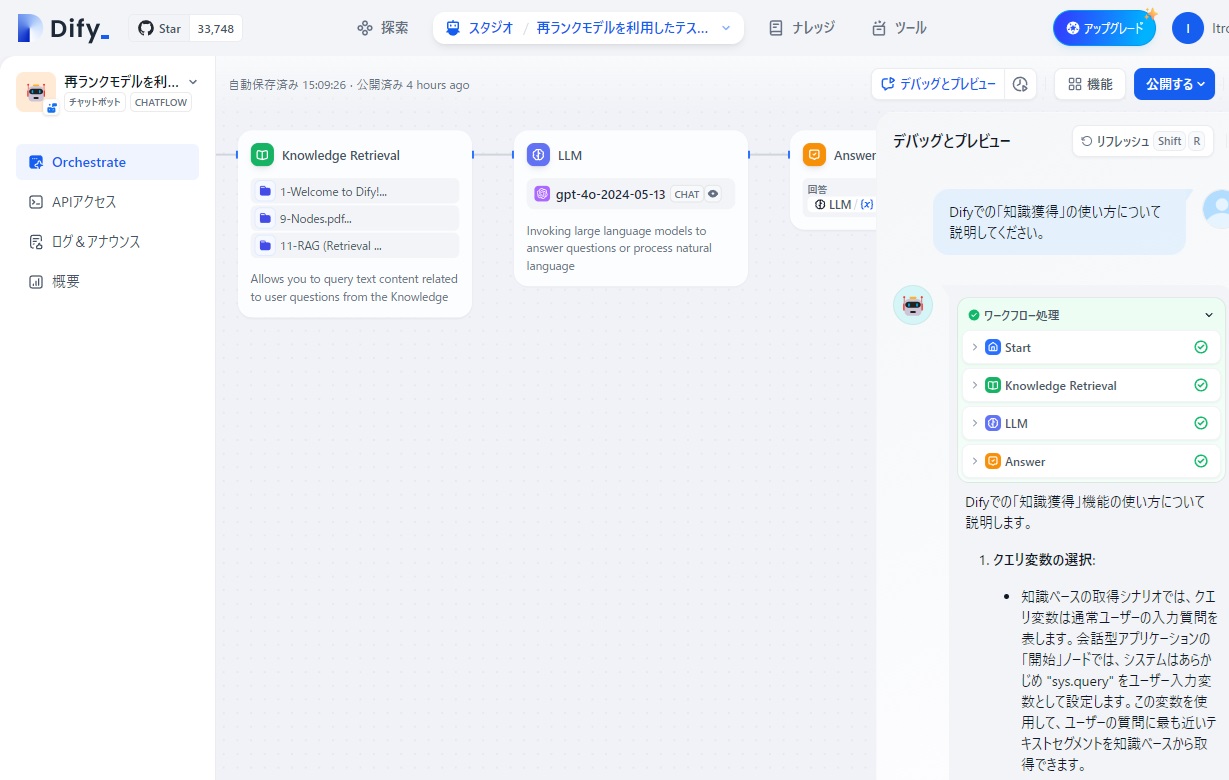
そこで、今度はワークフロー処理の「Knowledge Retrieval」の部分をクリックし、このノードの入出力の内容を確認します。
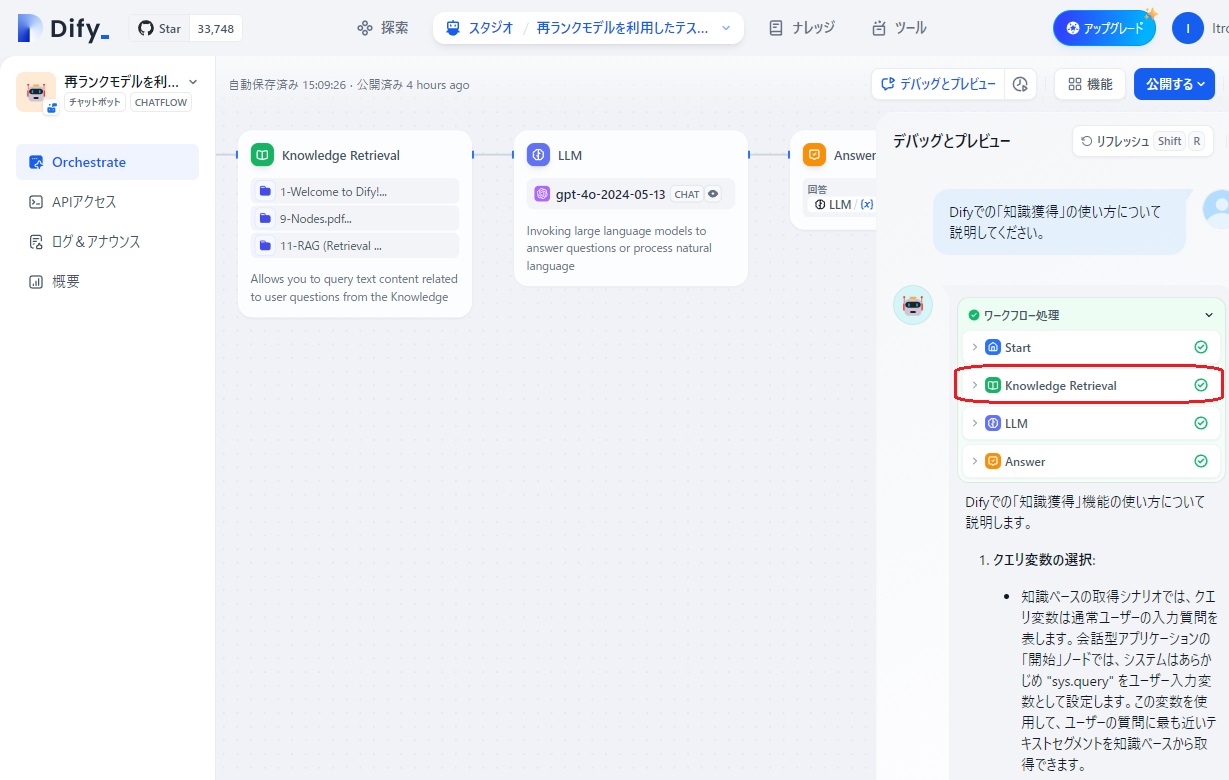
すると、下図のように「Knowledge Retrieval」ノードの入力データと出力データの一部が表示されました。
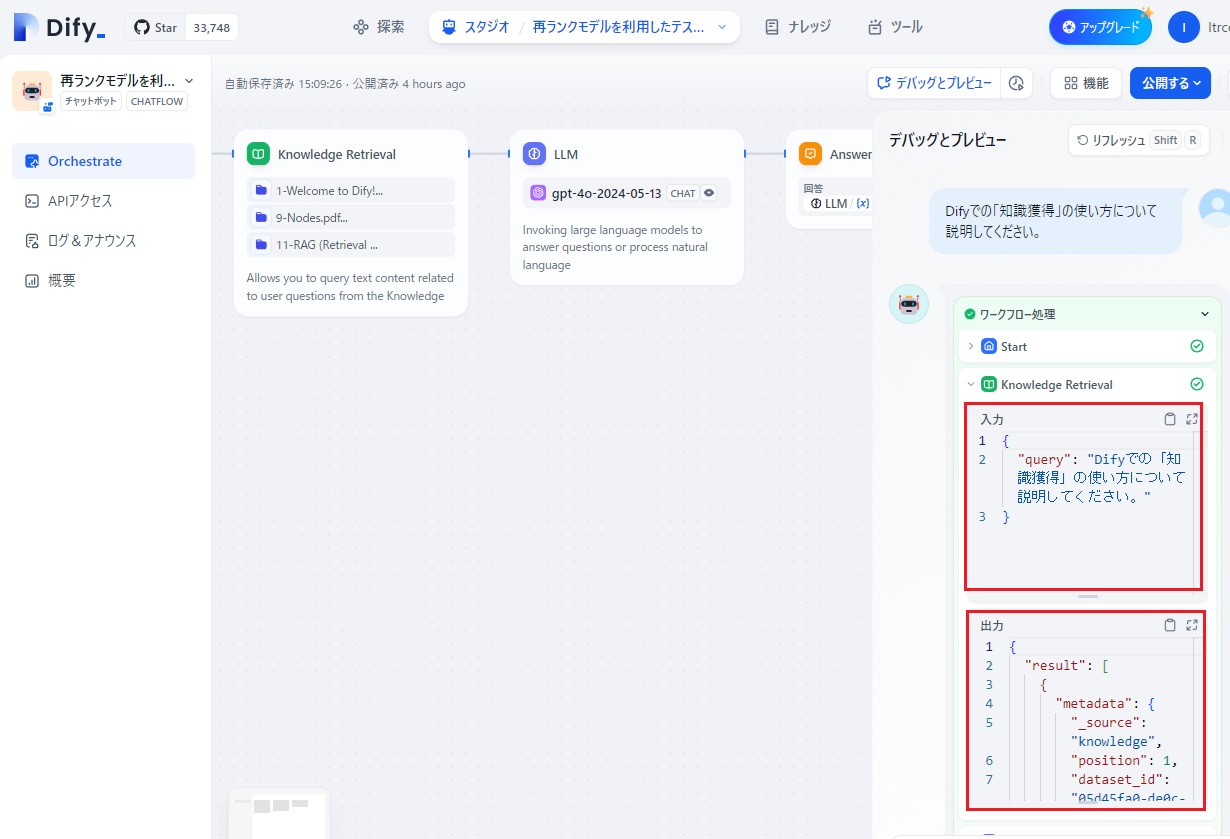
「Knowledge Retrieval」ノードには、入力データとして「Difyでの「知識獲得」の使い方について説明してください」がわたってきているのが分かります。
この入力に関連してRAG情報として「出力」部分には、以下のような内容が入っていました。
|
{ “result”: [ { “metadata”: { “_source”: “knowledge”, “position”: 1, “dataset_id”: “05d45fa0-de0c-4b00-9a43-441b7ce12e8e”, “dataset_name”: “9-Nodes.pdf…”, “document_id”: “c1b63fa3-25ae-4181-9aac-e9b726c9f655”, “document_name”: “9-Nodes.pdf”, “document_data_source_type”: “upload_file”, “segment_id”: “7b0ce9a8-8e8f-45ae-a7cc-96d951e5357e”, “retriever_from”: “workflow”, “score”: 0.99568534, “segment_hit_count”: 3, “segment_word_count”: 1013, “segment_position”: 13, “segment_index_node_hash”: “47b30d464144de658455c38b454e947a3f6c2d06d5d39bf623ce5eaac39b28b5” }, “title”: “9-Nodes.pdf”, “content”: “Knowledge Retrieval\r\nThe Knowledge Base Retrieval Node is designed to query text content related to user\r\nquestions from the Dify Knowledge Base, which can then be used as context for subsequent\r\nanswers by the Large Language Model LLM.\r\nConfiguring the Knowledge Base Retrieval Node involves three main steps:\r\n1. Selecting the Query Variable\r\n. Choosing the Knowledge Base for Query\r\n. Configuring the Retrieval Strategy\r\nSelecting the Query Variable\r\nIn knowledge base retrieval scenarios, the query variable typically represents the user’s input\r\nquestion. In the \”Start\” node of conversational applications, the system pre-sets \”sys.query\”\r\nas the user input variable. This variable can be used to query the knowledge base for text\r\nsegments most closely related to the user’s question.\r\nChoosing the Knowledge Base for Query\r\nWithin the knowledge base retrieval node, you can add an existing knowledge base from Dify.\r\nFor instructions on creating a knowledge base within Dify, please refer to the knowledge” }, { “metadata”: { “_source”: “knowledge”, “position”: 1, “dataset_id”: “f2d2f698-8bc6-4e64-b8c2-1acd40c03b09”, “dataset_name”: “11-RAG (Retrieval …”, “document_id”: “e72e5ca4-97e1-4903-a6da-b4a9e6b495a5”, “document_name”: “11-RAG (Retrieval Augmented Generation).pdf”, “document_data_source_type”: “upload_file”, “segment_id”: “e989b841-8049-46d9-9581-081a00433353”, “retriever_from”: “workflow”, “score”: 0.9470882, “segment_hit_count”: 2, “segment_word_count”: 839, “segment_position”: 14, “segment_index_node_hash”: “87d3e88609d6660dad32bb1067daefbd094d159d80a4fdef51db843204cf85f7” }, “title”: “11-RAG (Retrieval Augmented Generation).pdf”, “content”: “Retrieval\r\nWhen users build knowledge base Q&A AI applications, if multiple knowledge bases are\r\nassociated within the application, Dify supports two retrieval modes: N-to-1 retrieval and\r\nMulti-path retrieval.\r\nBased on user intent and knowledge description, the Agent independently determines and\r\nselects the most matching single knowledge base for querying relevant text. This mode is\r\nsuitable for applications with distinct knowledge and a smaller number of knowledge bases.\r\nN-to-1 retrieval relies on the model’s inference capability to choose the most relevant\r\nknowledge base based on user intent. When inferring the knowledge, the knowledge serves\r\nas a tool for the Agent, chosen through intent inference; the tool description is essentially the\r\nknowledge description.\r\nRetrieval Settings\r\nRetrieval Settings\r\nN-to-1 Retrieval” } ] } |
入力内容と類似度の高い「チャンク」として、9-Nodesの情報(文字色=緑)と、11-RAG (Retrieval Augmented Generation)の情報(文字色=青)の2つが選ばれているのが分かります。
これに対して、「ワークフロー処理」の下の「LLM」ノード部分をクリックして、LLMへの入力を確認すると:
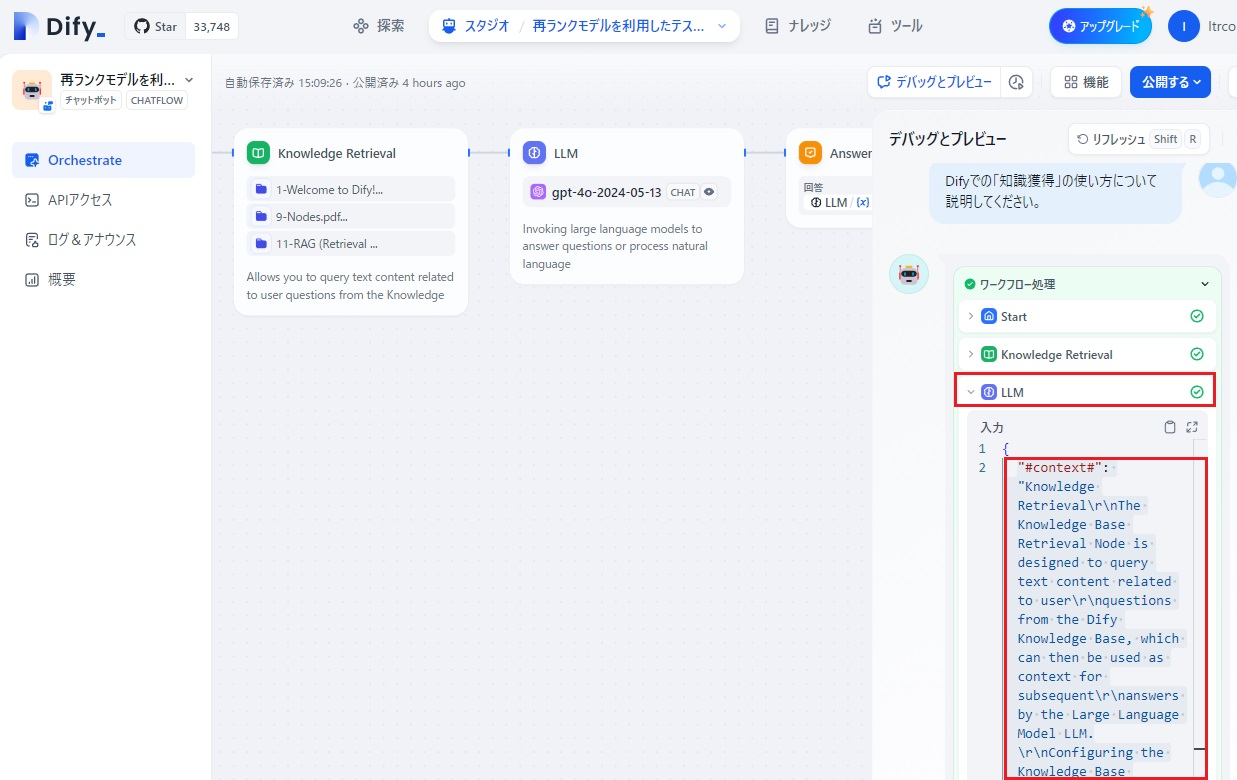
LLMの入力データすべてを見ると以下のようになっていました。
|
{ “#context#”: “Knowledge Retrieval\r\nThe Knowledge Base Retrieval Node is designed to query text content related to user\r\nquestions from the Dify Knowledge Base, which can then be used as context for subsequent\r\nanswers by the Large Language Model LLM.\r\nConfiguring the Knowledge Base Retrieval Node involves three main steps:\r\n1. Selecting the Query Variable\r\n. Choosing the Knowledge Base for Query\r\n. Configuring the Retrieval Strategy\r\nSelecting the Query Variable\r\nIn knowledge base retrieval scenarios, the query variable typically represents the user’s input\r\nquestion. In the \”Start\” node of conversational applications, the system pre-sets \”sys.query\”\r\nas the user input variable. This variable can be used to query the knowledge base for text\r\nsegments most closely related to the user’s question.\r\nChoosing the Knowledge Base for Query\r\nWithin the knowledge base retrieval node, you can add an existing knowledge base from Dify.\r\nFor instructions on creating a knowledge base within Dify, please refer to the knowledge\nRetrieval\r\nWhen users build knowledge base Q&A AI applications, if multiple knowledge bases are\r\nassociated within the application, Dify supports two retrieval modes: N-to-1 retrieval and\r\nMulti-path retrieval.\r\nBased on user intent and knowledge description, the Agent independently determines and\r\nselects the most matching single knowledge base for querying relevant text. This mode is\r\nsuitable for applications with distinct knowledge and a smaller number of knowledge bases.\r\nN-to-1 retrieval relies on the model’s inference capability to choose the most relevant\r\nknowledge base based on user intent. When inferring the knowledge, the knowledge serves\r\nas a tool for the Agent, chosen through intent inference; the tool description is essentially the\r\nknowledge description.\r\nRetrieval Settings\r\nRetrieval Settings\r\nN-to-1 Retrieval” } |
この内容を見ると、一旦、「Knowledge Retrieval」ノードでは、入力に関連する「チャンク」情報として、9-Nodesの情報と、11-RAG (Retrieval Augmented Generation)の情報の2つが選ばれていましたが、その2つの間で、再ランキングが行われ、次「LLM」ノードには、9-Nodesのコンテキストのみが渡されていることが確認されました。
で、後は、「Difyについてーその3」で定義した24個のDifyに関する情報を「Knowledge Retrieval」ノードに再ランキングモデルとして登録すれば、Difyに関して、Dify.AIのサイト情報すべてをカバーして、かつ、質問したのと同じ言語で回答してくれるチャットボットアプリ「Difyのことなら何でも聞いてください」の完成だ!と思ったのですが、実は現実はそう甘くありませんでした。
長くなってしまいましたので、その話は次回に。
終わり

{kind=link}