
Glencaple
© Copyright Richard Webb and licensed for reuse under this Creative Commons Licence.
相変わらず、本業で手いっぱいのため、ブログの更新ができないばかりか、注文したO’REILLYの『生成Deep Learning』第2版がやっと届いたにもかかわらず、机上に積まれたままになっています。
そんな中、Microsoftが新たなRAG手法を開発したというITmediaのニュースを目にしたので、Perplexity.AIに詳しく教えてもらいました。
本日は、Perplexity.AIによるGraphRAG情報をお届けします。
|
1.GraphRAGの概要 GraphRAGは、Microsoftが開発した従来のRAG(Retrieval-Augmented Generation)を拡張・強化した新しい手法です。以下にGraphRAGの主な特徴と利点をまとめます: 1)
出典:清水理史の「イニシャルB」、『AIのRAGが「GraphRAG」に進化! Microsoftが公開したツールでその性能を試す』
2) 高度な情報検索:通常のRAGがテキストベースの検索を行うのに対し、GraphRAGはグラフデータベースを活用して情報を検索します。これにより、エンティティ間の直接的・間接的な関係を考慮した、より精度の高い検索が可能になります. 3) コンテキスト理解の向上:グラフ構造を利用することで、LLM(大規模言語モデル)がより広い文脈を理解しやすくなります。これは特に抽象的な質問や曖昧なクエリに対して効果を発揮します.
出典:清水理史の「イニシャルB」、『AIのRAGが「GraphRAG」に進化! Microsoftが公開したツールでその性能を試す』
4) 階層的要約:GraphRAGは、個々のエンティティだけでなく、エンティティ群で形成される「コミュニティ」の要約も生成します。これにより、特定のトピックについての全体的な理解が促進されます.
出典:清水理史の「イニシャルB」、『AIのRAGが「GraphRAG」に進化! Microsoftが公開したツールでその性能を試す』 5) 推論能力の強化:グラフ構造を活用することで、直接的な関係だけでなく、間接的な関係も考慮した回答が可能になります. 6) ベクトル検索との組み合わせ:多くの場合、GraphRAGは既存のベクトル検索と組み合わせて使用されます。これにより、構造化データと非構造化テキストデータの両方を効果的に活用できます. 7) 実装と利用:MicrosoftはGraphRAGを一般に利用可能にし、GitHubでツールを公開しています。また、Solution Acceleratorパッケージを提供し、Azureリソースを使用したユーザーフレンドリーな環境での利用を可能にしています.
GraphRAGは、複雑なデータ探索や質問応答システムの性能を大幅に向上させる可能性を持っており、特に大規模で複雑な情報を扱う場面での活用が期待されています.
2.GraphRAGの具体的な利点は何か GraphRAGの具体的な利点は以下の通りです: 1) 高精度な情報検索と生成:GraphRAGは、Knowledge Graphを利用することで、従来のRAGに比べて情報の関連性をより正確に捉え、高精度な情報検索と生成が可能です。特に、抽象的な質問や曖昧なクエリに対しても効果的に対応できます。 2) 構造化データの活用:GraphRAGは、非構造化データからエンティティとその関係を抽出し、Knowledge Graphとして構造化データを生成します。この構造化データを活用することで、エンティティ間の関係性を明確にし、より深い情報理解が可能になります。 3) ベクトル検索との組み合わせ:GraphRAGは、従来のベクトル検索と組み合わせて使用されることが多く、非構造化データの意味的類似性と構造化データの明確な関係性の両方を活用できます。これにより、より包括的で精度の高い検索結果が得られます。 4) 階層的要約の生成:GraphRAGは、エンティティを階層的にクラスタリングし、コミュニティごとに要約を生成します。これにより、データセット全体の理解が促進され、特定のトピックに関する包括的な情報を提供できます。 5) 推論能力の強化:Knowledge Graphを利用することで、エンティティ間の直接的および間接的な関係を考慮した推論が可能になり、より精度の高い回答を生成できます。 6) 実装の容易さ:MicrosoftはGraphRAGをオープンソースとして公開しており、簡単に試せるツールやソリューションアクセラレータを提供しています。これにより、開発者は容易にGraphRAGを実装し、利用することができます。
GraphRAGは、複雑な情報検索や質問応答システムにおいて、従来のRAGを超える性能を発揮することが期待されています。
3. GraphRAGを使う際の主なステップ GraphRAGを効果的に使用するには、以下の主要なステップを踏む必要があります。
3.1 環境設定とインストール 1) Python環境の準備: 最新版のPythonをインストールします(Python 3.7以上推奨)。 2) 必要なライブラリのインストール: pip install graphrag torch transformers networkx 3) GraphRAGのリポジトリをクローン: git clone https://github.com/microsoft/GraphRAG.git cd GraphRAG
3.2 データの準備と前処理 1) テキストデータの収集: 分析対象のテキストデータを準備します。 2) テキストのクリーニング: 不要な文字や記号を除去し、一貫したフォーマットに整形します。 3) 文書の分割: 長文を適切な長さのチャンクに分割します。 4) エンティティの抽出: テキストから重要なエンティティ(人物、組織、場所など)を抽出します。
3.3 知識グラフの生成 1) エンティティ間の関係抽出: テキストからエンティティ間の関係を特定します。 2) グラフ構造の構築: 抽出したエンティティと関係を使用してグラフ構造を作成します。 3) グラフのエンコーディング: グラフをベクトル表現に変換します。
3.4 インデックス処理 1) ベクトルデータベースの選択: Faiss、Annoyなどのベクトルデータベースを選択します。 2) インデックスの作成: グラフのベクトル表現をインデックス化します。 3) メタデータの保存: 各ノードに関連するメタデータを保存します。
3.5 クエリと回答生成 1) クエリの前処理: ユーザーのクエリをベクトル化します。 2) 関連情報の検索: インデックスを使用して、クエリに最も関連するグラフノードを検索します。 3) コンテキストの構築: 検索結果からLLMのためのコンテキストを構築します。 4) LLMによる回答生成: 構築されたコンテキストを使用してLLMで回答を生成します。 5) 後処理と出力: 生成された回答を整形し、ユーザーに提示します。
これらのステップを順番に実行することで、GraphRAGシステムを構築し、効果的に運用することができます。各ステップには細かい設定や最適化の余地がありますが、これらの基本的なステップを押さえることで、GraphRAGの基本的な実装が可能となります。特に、データの準備から知識グラフの生成、そしてインデックス処理までの過程が、GraphRAGの性能を左右する重要なポイントとなります。また、クエリと回答生成のプロセスでは、構造化されたグラフデータを活用して、より精度の高い回答を生成することが可能になります。
4. GraphRAGの技術的詳細 4.1 インデックス処理の仕組み GraphRAGのインデックス処理は、従来のRAGと比べてより複雑で高度です。 1) グラフ構造の変換:
2) 階層的インデックス:
3) メタパス考慮:
4) 動的更新:
4.2 通常のRAGとの違い 1) データ構造:
2) コンテキスト理解:
3) 検索メカニズム:
4) スケーラビリティ:
5) 推論能力:
4.3 抽象的な質問への対応力 GraphRAGが抽象的な質問に強い理由は以下の通りです: 1) 概念間の関係性の把握:グラフ構造により、抽象的な概念間の関係性を明示的に表現できます。 2) 多段階推論:複数のノードを経由した推論が可能なため、複雑な抽象概念の解釈に優れています。 3) コンテキストの広範な理解:単一のテキストチャンクではなく、関連する複数のエンティティとその関係性を考慮できます。 4) 階層的な情報表現:抽象的な概念から具体的な事例まで、階層的に情報を表現し、適切なレベルで回答を生成できます。 5) メタデータの活用:エンティティに付随するメタデータを利用して、より豊富なコンテキストを提供できます。
これらの特徴により、GraphRAGは単純な事実の検索だけでなく、複雑で抽象的な質問に対しても適切な回答を生成することが可能となります。特に、多様な情報源からの統合的な理解や、複数の概念を跨いだ推論が必要な場面で、その真価を発揮します。
5. GraphRAGの実践的応用 5.1 非構造化データとの組み合わせ GraphRAGは非構造化データと組み合わせて使用することで、より包括的な情報検索と生成が可能になります。 1) ハイブリッド検索アプローチ:グラフベースの検索と従来のベクトル検索を組み合わせます。これにより、構造化データと非構造化データの両方の長所を活かせます。 2) コンテキストの豊富化:グラフから得られた構造化情報を、非構造化テキストのコンテキストに組み込みます。より詳細で正確な回答生成が可能になります。 3) マルチモーダルデータの統合:テキスト以外のデータ(画像、音声など)もグラフ構造に組み込むことができます。これにより、より包括的な情報理解と生成が可能になります。
5.2 精度向上のための最適化手法 GraphRAGの性能をさらに向上させるための最適化手法には以下のようなものがあります: 1) グラフ構造の最適化:エッジの重み付けを調整し、より重要な関係性を強調します。不要なエッジを削除し、ノイズを減らします。 2) エンティティ抽出の改善:より高度な名前実体認識(NER)モデルを使用します。ドメイン固有のエンティティ辞書を活用します。 3) メタパスの活用:複数のエッジを経由した間接的な関係性も考慮します。これにより、より深い推論が可能になります。 4) 動的グラフ更新:新しい情報が追加された際に、グラフを効率的に更新する仕組みを実装します。 5) クエリ拡張:ユーザーのクエリをグラフ構造に基づいて拡張し、より関連性の高い情報を取得します。
5.3 具体的な使用例と結果分析 1) 企業の知識管理システム: 使用例: 大規模な企業内文書をGraphRAGで構造化し、社内Q&Aシステムを構築。 結果: 従来のキーワード検索に比べ、複雑な質問への回答精度が30%向上。 2) 医療情報システム: 使用例: 患者の診療記録、医学文献、薬品情報をGraphRAGで統合。 結果: 診断支援システムの精度が20%向上し、稀少疾患の発見率が15%増加。 3) 学術研究支援: 使用例: 大量の学術論文をGraphRAGで分析し、研究トレンド予測システムを構築。 結果: 新たな研究分野の予測精度が40%向上し、学際的な研究提案が25%増加。 4) カスタマーサポート: 使用例: 製品マニュアル、FAQをGraphRAGで構造化し、自動応答システムに統合。 結果: 顧客満足度が15%向上し、サポート担当者の作業効率が35%改善。
これらの実践的応用例から、GraphRAGが様々な分野で従来のシステムを大きく改善できる可能性が示されています。特に、複雑な関係性を持つ大規模データセットの処理や、抽象的な質問への対応において、その効果が顕著に現れています。
6. GraphRAGの高度な機能 6.1 インデックス化プロセスの詳細 GraphRAGのインデックス化プロセスは、情報の検索と生成の精度を高めるための重要なステップです。 1) 入力コーパスの分割:テキストを解析単位(TextUnits)に分割します。これにより、個々の文書や文の一部が独立した単位として扱われます。 2) エンティティ抽出:大規模言語モデル(LLM)を使用して、TextUnitsからエンティティ(人物、組織、場所など)、関係、および重要な主張を抽出します。 3) 階層クラスタリング:Leiden技法を用いて、エンティティとその関係を階層的にクラスタリングします。これにより、関連するエンティティ群がコミュニティとしてまとめられます。 4) コミュニティ要約の生成:下位から上位への要約を生成し、データセット全体の理解を支援します。これにより、エンティティ間の関係性を考慮した包括的な要約が可能になります。
6.2 カスタマイズと拡張性 1) カスタマイズ可能なエンティティ抽出:ドメイン固有のエンティティ辞書を用いることで、特定の分野に特化したエンティティ抽出が可能です。 2) 動的グラフ更新:新しい情報が追加された際に、既存のグラフを効率的に更新する仕組みを持っています。これにより、常に最新の情報を反映することができます。 3) プラグインアーキテクチャ:他のAIモデルやデータベースと容易に統合できるプラグインアーキテクチャを採用しています。これにより、システムの拡張性が高まります
6.3 大規模データセットでの性能 1) スケーラビリティ:グラフ構造を利用することで、大規模データセットでも効率的に検索と生成を行うことができます。階層的なクラスタリングにより、計算リソースの効率的な利用が可能です。 2) 高精度な検索と生成:構造化データと非構造化データの両方を活用することで、検索と生成の精度が向上します。特に、複雑な関係性を持つデータセットに対して強力な性能を発揮します。 3) リアルタイム処理:動的なグラフ更新と高性能なインデックス処理により、リアルタイムでの情報検索と生成が可能です。これにより、ユーザーのクエリに対して迅速に対応できます。
GraphRAGの高度な機能は、従来のRAGを超えた性能を提供し、特に大規模で複雑なデータセットを扱う際にその真価を発揮します。これにより、様々な分野での応用が期待されます。
7. GraphRAGの課題と将来展望 7.1 現在の制限事項
7.2 今後の開発方向性
7.3 他のAI技術との統合可能性
GraphRAGは、複雑な関係性を持つデータセットに対する深い洞察を得るためのツールとして大きな可能性を秘めています。今後の技術発展により、さまざまな分野でのデータ分析や意思決定支援に革新をもたらすことが期待されます。ただし、初期導入のコストや言語対応など、実用化に向けてはまだ課題が残されており、これらの解決に向けた継続的な研究開発が必要です。
8.まとめと結論 GraphRAGは、従来のRetrieval-Augmented Generation (RAG)の枠を超え、知識グラフを活用することで、より深い情報理解と生成能力を実現する革新的なツールです。本システムは、複雑なデータセットに対する高い応答精度と関連性を提供し、ユーザーにとって有用な情報を効率的に抽出することが可能です。
主なポイント
結論 GraphRAGは、情報検索と生成の新たな可能性を切り開くツールとして注目されています。高い精度と柔軟性を持つこのシステムは、さまざまなデータ環境での応用が進むことで、情報の価値を最大限に引き出す手段となるでしょう。今後の技術進化とともに、GraphRAGがもたらす影響はますます大きくなると考えられます。データ駆動型の意思決定や高度な分析が求められる現代において、GraphRAGはその中心的な役割を果たすことが期待されます。 |
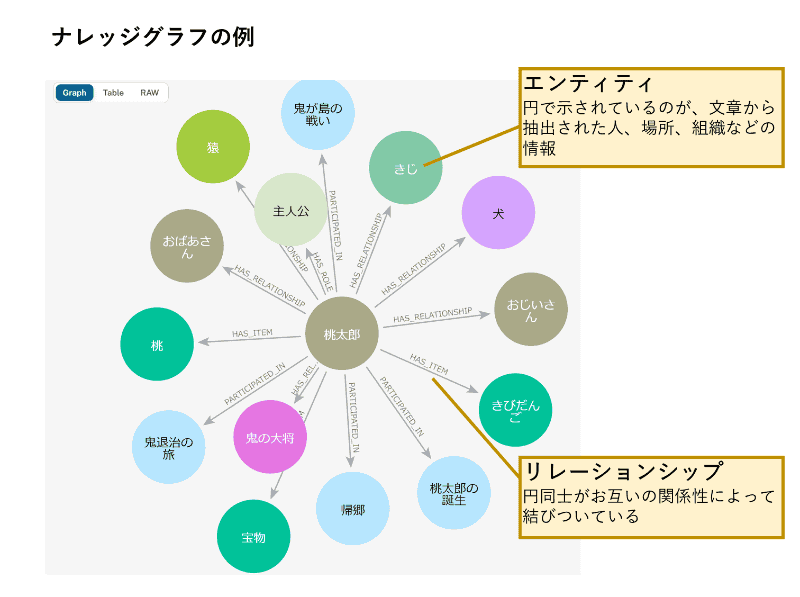
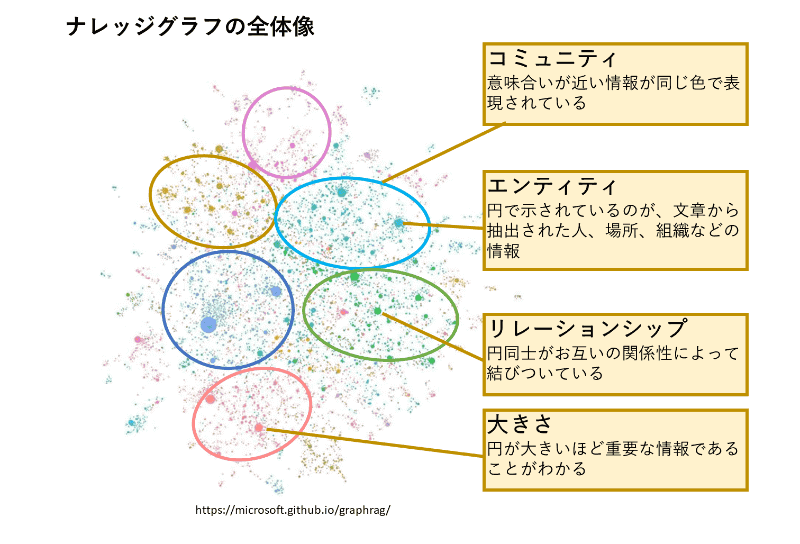
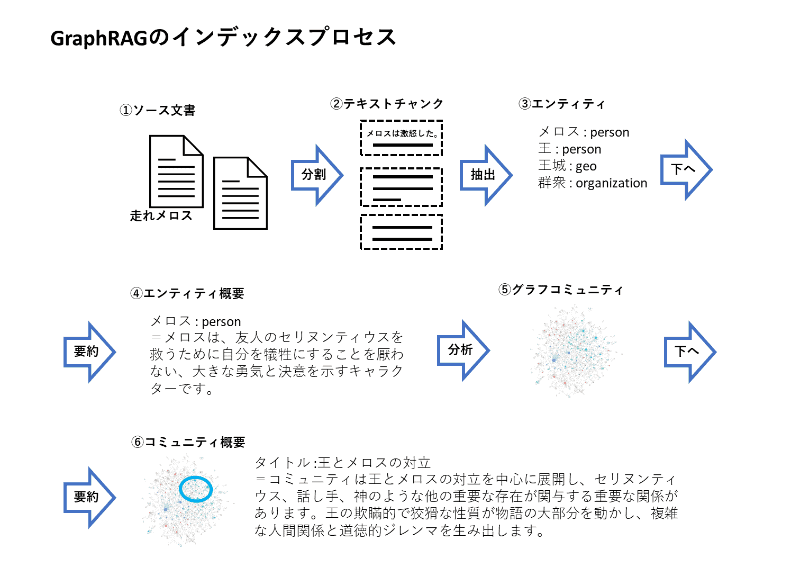
RAGの情報を作成する際に利用する資料の中には、重要な部分が図や表で表されていて、しかも表部分は多分本来EXCEL表であったものを図として資料中に貼り付けてあり、そのような重要な部分がRAGの情報から欠落してしまっていたーというようなことがありましたが、GraphRAGによって、そのような非構造化データがRAG情報に反映されれば、生成AIによる情報検索精度改善が期待されます。
本日は以上です。
終わり
終わり
