
Thatched cottage at Sarson
© Copyright David Martin and licensed for reuse under this Creative Commons Licence.
当インターテックリサーチのブログ内容がAI検索できるようになりましたのでお知らせします。
ブログのページを表示している時だけ、下図の通り、画面右端に赤枠で囲ったように、ブログ内のテキストのAI検索ができる「小窓」が表示され、最下行に、検索したい内容を入力してメール送信ボタンをクリックしてもらえば、ブログコンテンツのみを参照して結果が表示されます。
ご自身のブログに、AI検索機能を導入したい方もいらっしゃると思いますので、今回は、AI検索機能をブログに導入した手順をご紹介します。
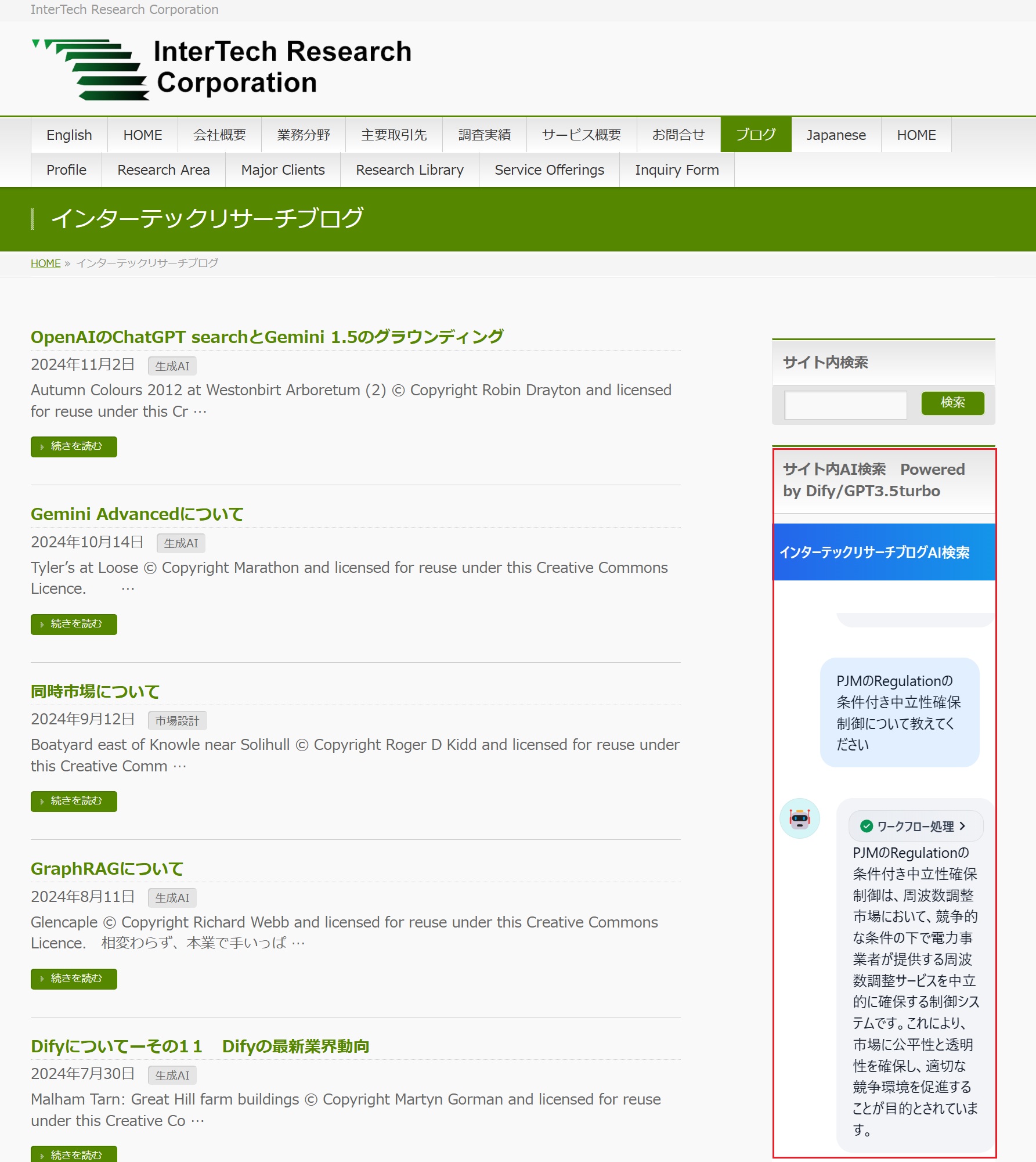
「サイト内AI検索 Powered by Dify/GPT3.5turbo」と表示しているように、このAI検索はDifyのRAGデータ作成機能を利用して、インターテックリサーチのブログ原稿全てをDifyに「ナレッジ」として取り込み、入力された情報にマッチする情報を後段のLLM(それほどLLM自体には高度な判断をさせないので、OepnAIのgpt3.5-turboにしました)に渡し、LLM側で回答の文章を作って表示させています。
以下が、その処理ワークフローです。

「KNOWLEDGE RETRIEVAL」の「インターテックリサーチブログテキスト」の部分が、DifyのRAGデータベース作成機能を利用して作成した「ナレッジ」です。
まずは、Dify v0.6.11で利用可能になった、指定したウェブサイト内の全てのアクセス可能なサブページを巡回し、それぞれのページのデータを収集してくれるというFirecrawlを試してみました。(下図参照)
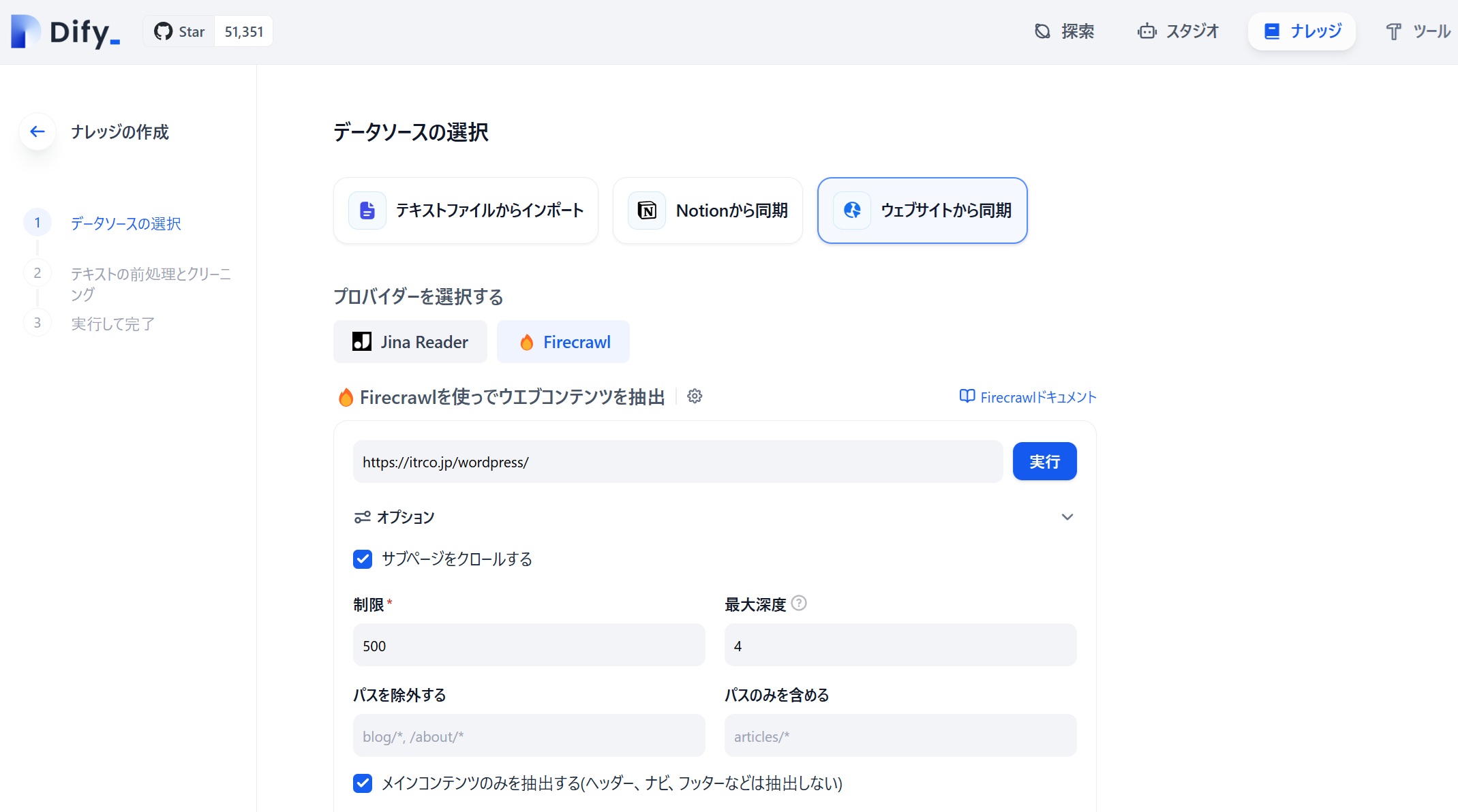
- 「Firecrawlを使ってウェブコンテンツを抽出」と表示されている下の入力欄には、ブログページのルートのURL(https://www.itrco.jp/wordpress/)を指定
- 当インターテックリサーチブログで利用しているWordpressでブログ原稿を作っている場合、年(例:https://www.itrco.jp/wordpress/2024)と月(https://www.itrco.jp/wordpress/2024/11)でレベルが深くなるので、3レベルでよいと思ったのですが「最大深度」の入力欄には4にを指定
- また、現在ブログの原稿数は400以上ありますので、「制限(収集するページ数の制限)」の入力欄には500を指定
として、実行してみました。
これは便利だ!と思ったのですが、ルート、年、月レベルのいずれのURLを指定しても、5ページ分しか抽出してくれません。
DifyからFiewcrawlを呼びだすには、Firecrawlが発行するAPIをDifyに設定するのですが、無料アカウントで発行されたAPIの場合、5ページ分しか返してくれない仕様なのかもしれません。(と思い、一旦諦めました←補足参照)
- Zennの「Firecrawlをローカルで動かしDifyと繋げてみる」では、「SaaS版のFirecrawlは無料だと500回のリクエスト制限がある」となっていたので、500回なら大丈夫だと持ったのですが。
Difyは、ウェブサイトを指定するだけで、自動的に画面データを抽出してくれる「プロバイダー」として、もう1つJina Readerを用意しています。
しかし、サイトを確認したところ、こちらも有料でなければ使えなさそうなので、データソースの選択」機能の1つとしてDifyが提供してくれている「ウェブサイトから同期」という機能を利用をするのをあきらめ、「テキストファイルからインポート」することにしました。
と言っても、400以上あるブログ原稿を1つ1つ手でダウンロードするのでは、日が暮れてしまいます。
ラッキーだったのは、ブログ原稿をWordpressで作っていたことでした。
ChatGPTに何か良い手立てがないか相談したところ、ブログ原稿を一括してHTMLやWord形式でダウンロードしてくれる「Print My Blog」というWordpressのプラグインがあるというのです!!
早速このプラグインをWordpressの管理画面からインストールし、無料の「クイックプリント」機能で全原稿をPDFでダウンロード完了。
ただ、ダウンロードしたファイルのサイズが336MBもあり、このままではDifyが読み込めません(ナレッジの取り込みでDifyがテキストファイルを読み込む場合の最大サイズは15MBになっています)
どのみち、PDF中の画像ファイルはDifyのRAGデータ作成時には利用されないので、PDFからテキスト部分のみを抜き出したところ、ファイルサイズが6MBと小さくなり、テキストファイルをインポートする際のファイルサイズ制限問題はクリアできました。
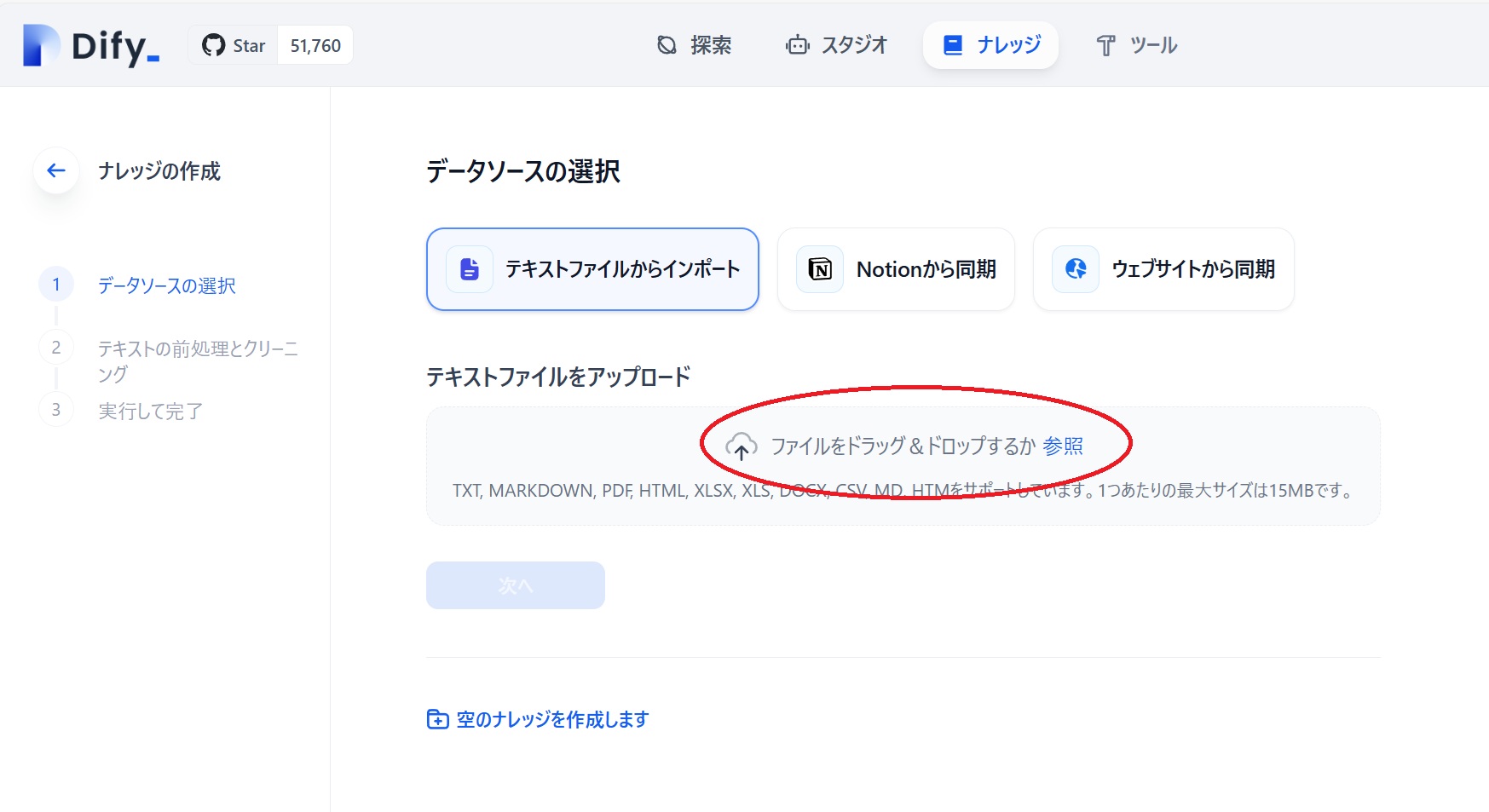
そこで、Difyのメニューで「ナレッジ」➡「ナレッジを作成」➡「テキストファイルからインポート」と辿って、Wordpress側で作成したテキストファイルを読み込ませました。
そして、Difyのメニューの「スタジオ」➡「チャットボット」➡「テンプレートから作成」➡「知識リトリーバル+チャットボット」(下図の赤枠)を選んで処理フローの大枠を作ります。
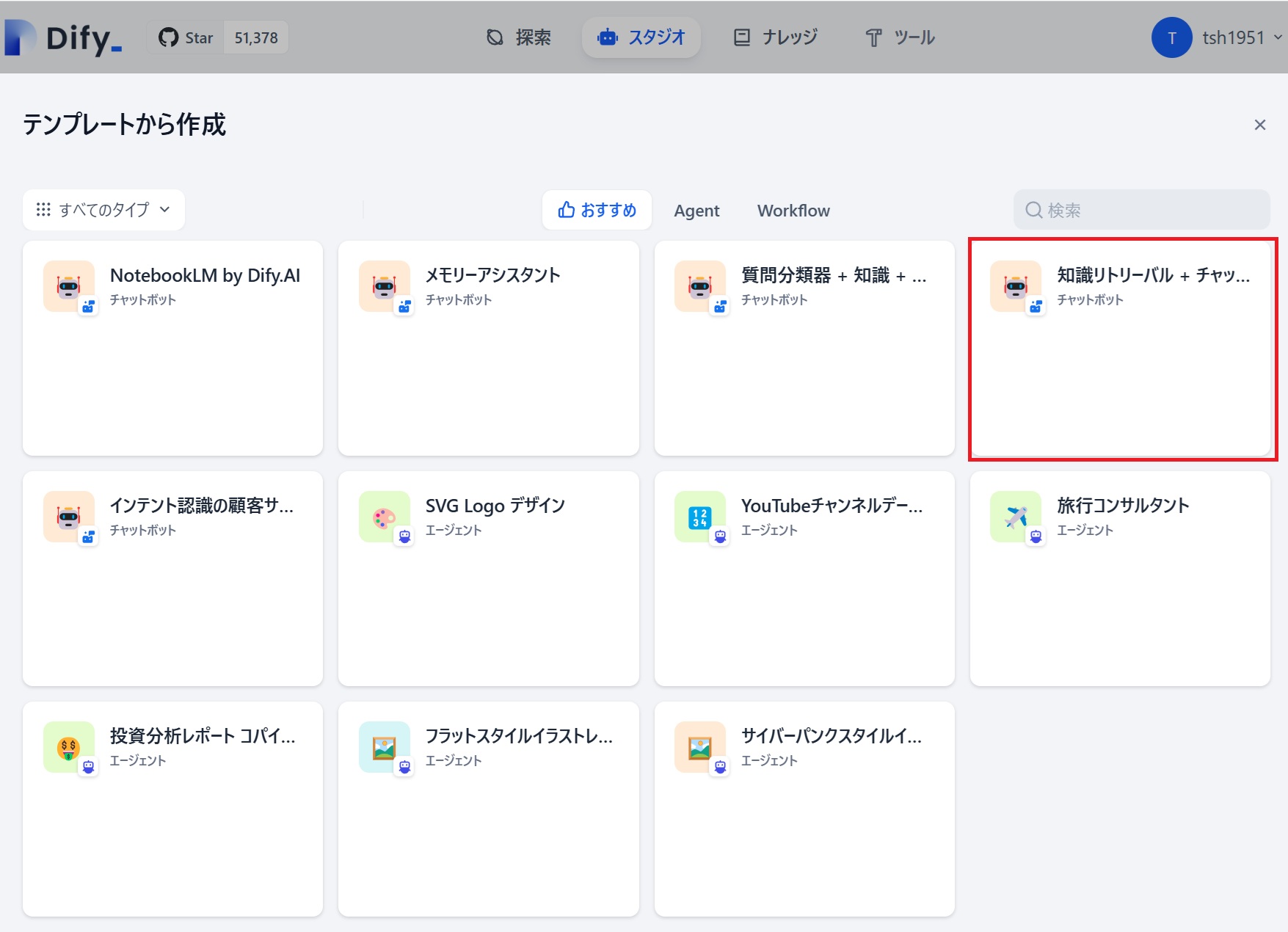
これで、最初にお見せした、RAGデータベースを利用して生成AIを呼び出すフローの大枠が出来上がりです。
後は、KNOWLEDGE RETRIEVALの「ナレッジ」に、先ほど作成した「インターテックリサーチブログテキスト」を指定。(下図赤枠参照)
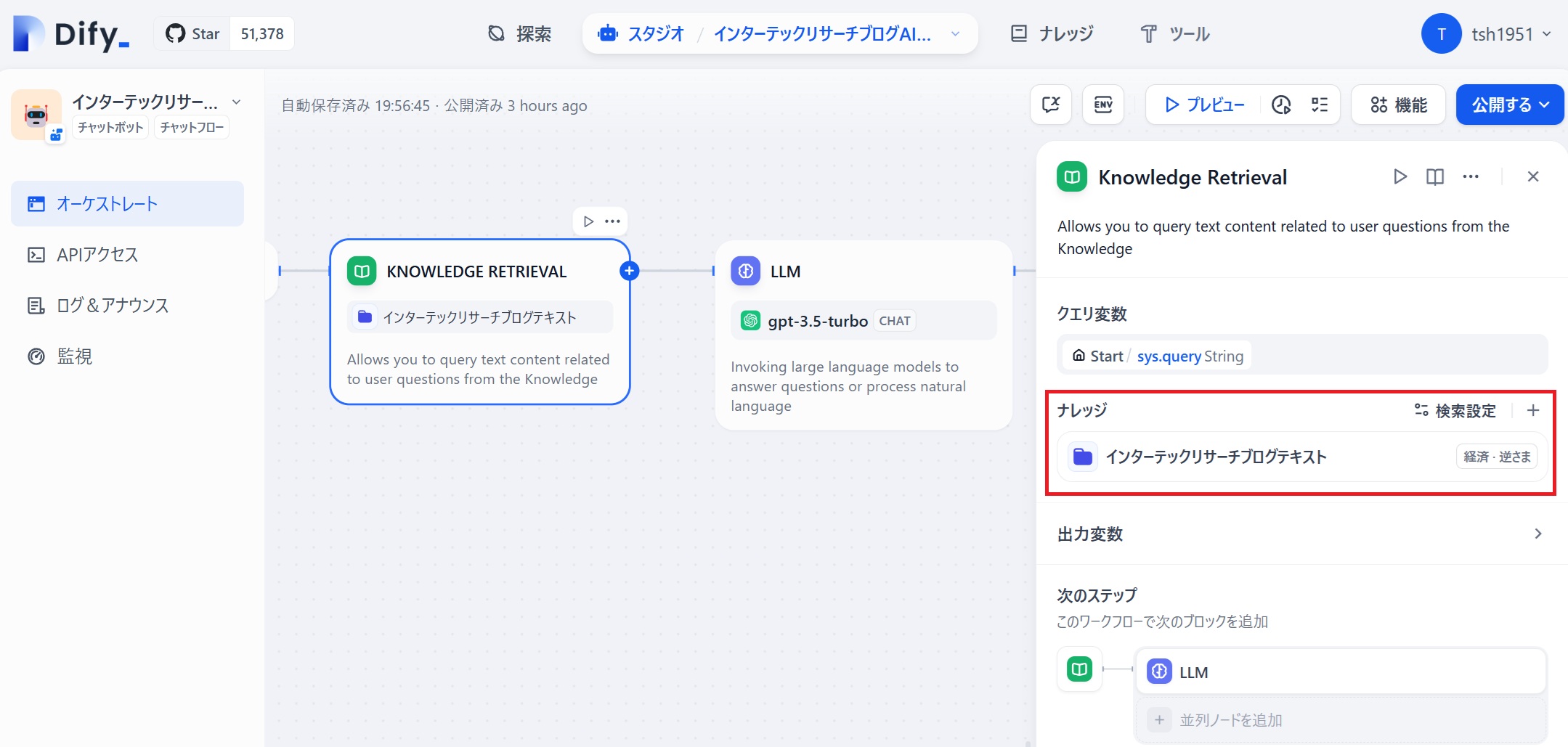
LLMの「コンテキスト」には、インターテックリサーチブログテキストのRAGデータベースで、START時の入力データと一番マッチするデータを結果(result)として受け取るため、resultを指定します。(下図赤悪参照)
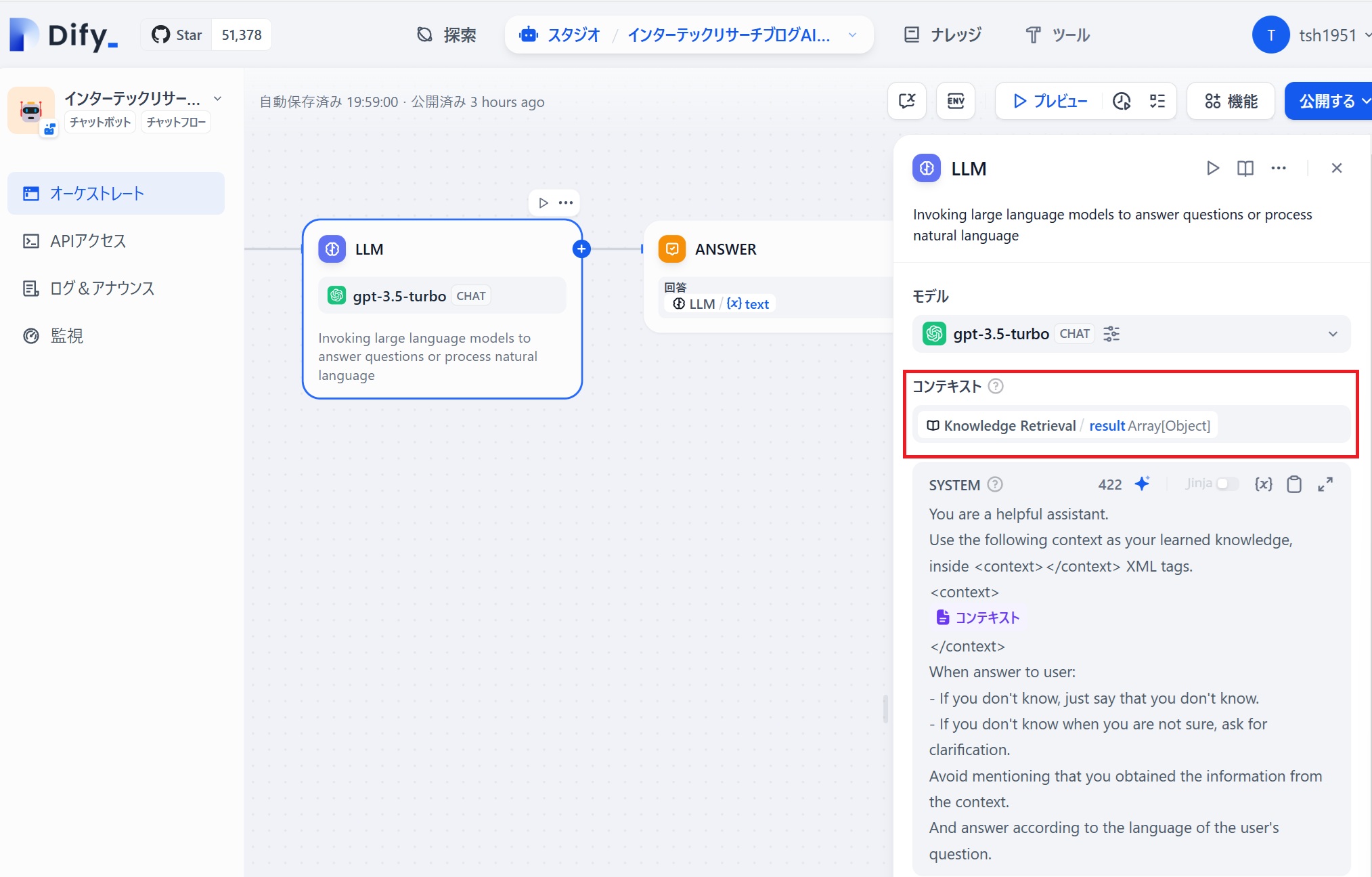
で、ANSWERの「回答」に、LLMが作成した回答(text)を指定すれば、インターテックリサーチブログのテキストベースで回答を作成するチャットボットが完成です。(下図赤枠参照)
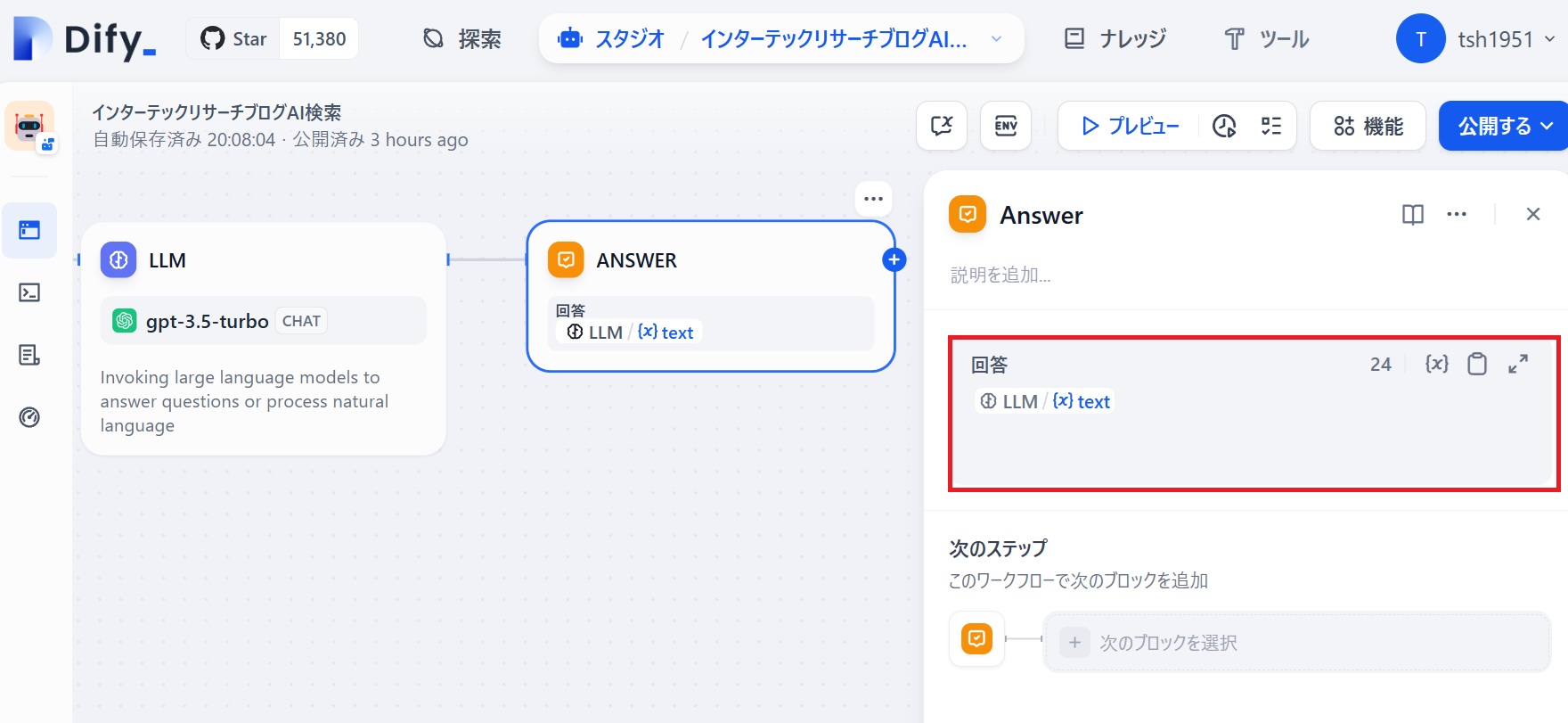
この後「公開する」をクリックすることで、だれからでもインターテックリサーチブログの内容をAI検索することが可能となる以下のURLが発行されました。
https://dify.itrcorp.org/app/eeee3132-f5fd-4d40-85a3-11eabee815fe/workflow
このURLを見るとわかるように、実は、今回Dify用に自前のサーバを立ち上げました。ドメインはブログと同じitrco.jpではなく、itrcorp.orgを使っています。
本当は、ブログと同じitrco.jpのドメイン(Xserverのレンタルサーバ)上にDify環境を構築したかったのですが、こちらのサーバでのDify実行環境構築が認められなかったため、新たにXserver VPSを利用することにしました。
※ Xserver VPSの「VPS」は「Virtual Private Server(仮想専用サーバ)」の略で、物理サーバを仮想化技術によって分割し、複数の独立した仮想サーバとして提供するサービスです。Xserver VPSは、従来インターテックリサーチで利用していたXserverレンタルサーバとは別の新たなサービスで、こちらの場合、仮想ではあっても「自前」のサーバなので、好きな環境を設定して使えるという訳です。
そして、Xserver社では、Xserver VPS提供にあたって、いろいろな種類のOSや、Dify等のアプリケーションが簡単にインストールできるサービスが提供されていましたので、思いのほか簡単にDifyサーバとして立ち上げることができました。
※それでも、いろいろわからないことがあり、Xserver社のサポートの方にお世話になりました。
最後に、このようにしてできた「インターテックリサーチブログAI検索の小窓」を、Wordpressのブログ表示画面に埋め込む作業が残っていますが、これもDifyがサポートしてくれます。
「公開する」ボタンをクリックして現れるサブメニューのうち「サイトに埋め込む」をクリックすると、下図左下の画面「ウェブサイトに埋め込む」がポップアップし、埋め込みコードを表示してくれるので、それをコピーし、Wordpress管理画面から「概観」➡「ウィゼット」➡「サイドバー投稿ページ」に貼り付ければ完了。
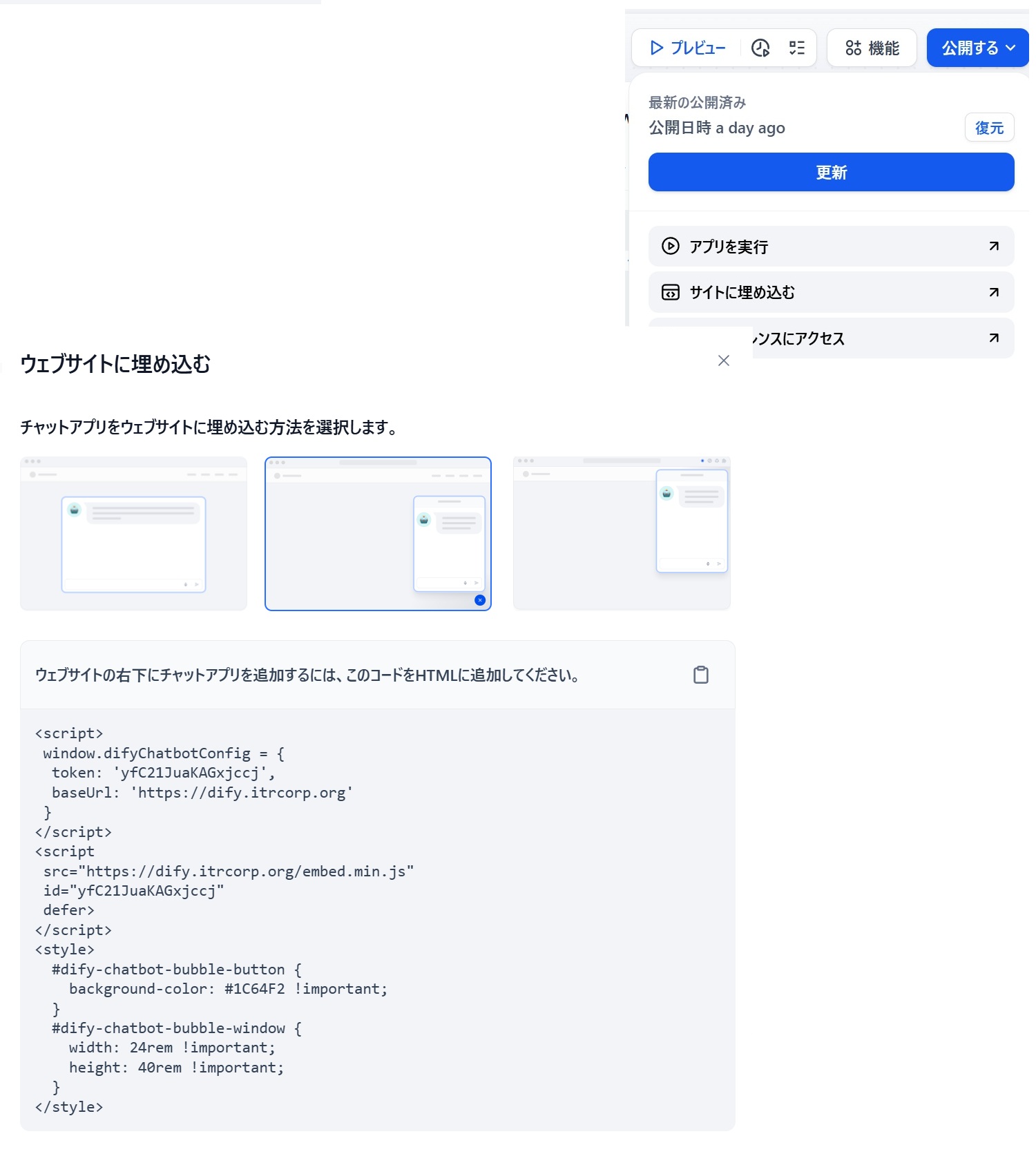
出来上がったAI検索は、1種類のナレッジ(インターテックリサーチブログテキスト)しか使っていないので、再ランクモデルは使用せず、すごくシンプルなRAGアプリになっています。
本当はブログ原稿内にある画像ファイルを使ってビジュアルな回答を作成させたいですが、現在のDifyの機能では、そこまでは望めません。DifyのRAGデータベース作成機能がはやく、テキストベースのRAGからGraphRAGに進化してほしいものです。
本日は以上です。
終わり
補足です:
Firecrawlですが、制限(ページ数の最大)を500にしたのがまずかったようです。
200に設定したところ、画面抽出は完了したのですが、それでは使えないので、制限値を450 (結果NG)➡ 400(結果NG)➡300 (結果NG)とサイトからの画面抽出のトライを続けるうちに「Failed to start crawl job. Status code: 402. Error: Insufficient credits. You may be requesting with a higher limit than the amount of credits you have left. If not, upgrade your plan at https://firecrawl.dev/pricing or contact us at help@firecrawl.com」のエラーが出てしまいました。
Jina Readerについても、API Keyの発行画面の最下行に無料のAPI Keyが示されていたので、これをDifyの設定 ➡ データソース ➡ Jina REaderのAPI Key欄に設定し、Firecrawl同様、Difyの画面からナレッジ ➡ ナレッジを作成 ➡ ウェブサイトから同期 ➡ プロバイダーを選択する = Jine Readerとし、「サブページをスクロールする」にチェックを付け、制限値を450 ➡ 400 ➡ 300 ➡ 200 ➡ 100と次第に小さくしていったところ、制限値=100でやっとサブページのスクロールを始めましたが、それより大きな数値を制限値として指定するとエラーとなってしまいました。
従って、いずれのツールも今回は利用できませんでした。
Difyで用意された「ウェブサイトから同期」の機能が使えればよかったのですが、インポートする内容が大きな場合うまくいかないとわかったことが、今回の1つの成果?です。
ただ、ナレッジのテキストファイルのインポートの最大サイズの制限である15MBが変更であることはYoutube「話題のDifyを使う上での注意点と設定方法について解説してみた」でにゃんたさんが解説してくれていたので、ウェブサイトから同期する場合も、どこかのパラメタを変更すれば、制限が解除できるかもしれません。
